DWS -- 前端制品服务的云原生部署实践
提示
云原生是一个很热门的话题,它将服务高可用性上升到了一个新的台阶。站点的高可用同时也是我们前端对自己的高要求。
那么我们该如何设计,才能让我们的前端项目也搭上云原生的快车,实现自动化运维与部署呢?本篇文章我们就来浅谈一下这里的实践。
从一个后台服务的部署开始
说到一个服务的部署,无论是本地起一个 Dev Server 用来做热加载,还是在某台服务器上起一个 Mock Server,用来实现数据通信,相信大家都有所实践。
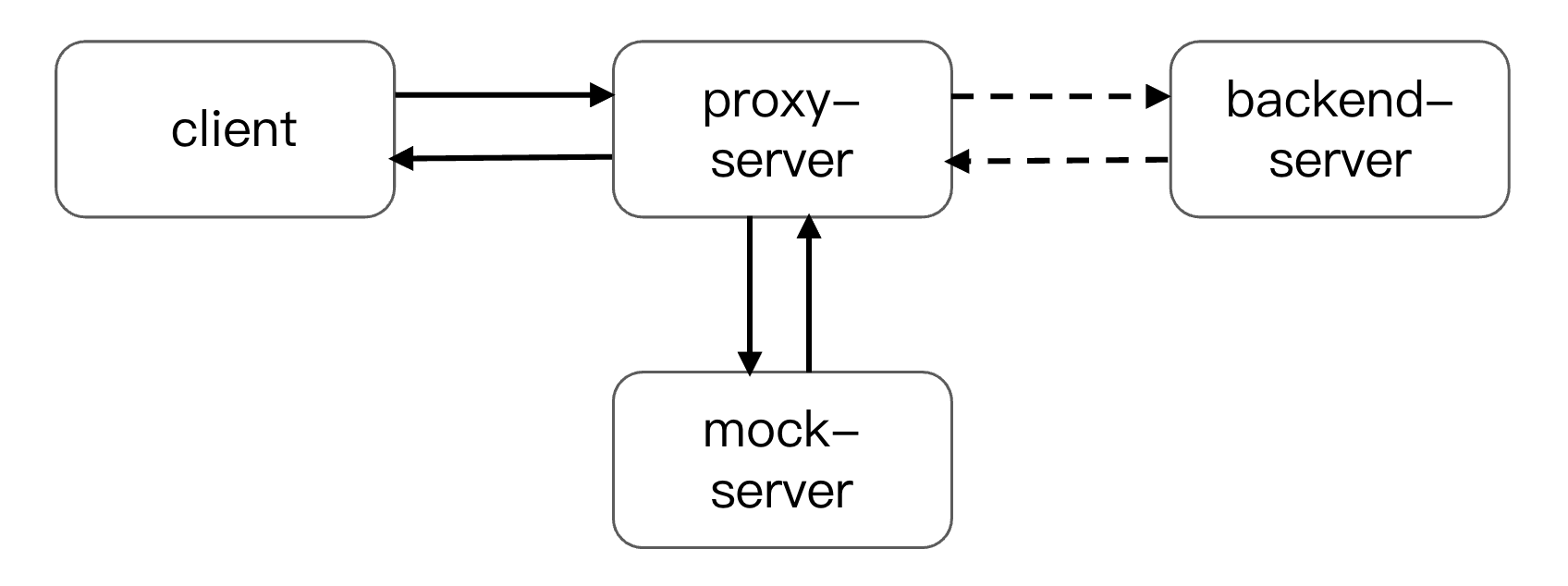
通常由我们前端开发搭建的后台服务,多以非关键链路为主,很少会去考虑稳定性和安全性的问题。遇到特性服务出现异常时,最常见的做法就是设计一个降级策略,如果出现任何问题告警,直接手动关闭该特性,把请求切换到某一个兜底的后台服务上。
但是,在服务宕机的这段时间内用户的异常率会上升,特性功能关闭某些后用户的体验也会下降。这样的降级策略并不优雅,甚至在某些关键链路的场景下,服务宕机会导致直接白屏,这是不可接受的。
工业级别的大型软件服务对稳定性有着近乎苛刻的要求。我们在网上浏览各大厂的服务架构介绍时,有一个词总是越来越频繁的出现,那就是云原生部署。
说到云,大家很容易想到各项云服务。有同学会说了,当前各厂都推出了公有云服务,既然这项技术已经这么发达了,我随便在腾讯云上买一台 CVM 当服务器,在上面进行服务的开发与部署,是不是就是服务的云原生部署了?事实上,云原生部署远不是单机服务上云这么简单。
云原生是以容器、微服务、DevOps 等技术为基础建立的一套架构思想,其核心在于利用了镜像服务的不可变特性,使得基于镜像的分布式以及自动化能力得以实现。
这么说可能不太好理解,我们可以换个思路,思考一个理想的服务架构应该要满足什么条件:
- 维护服务的稳定性,在任何场景下服务不能被中断,更新及回滚时要维持服务内容的幂等性,并对运行各迭代版本的服务做好充分的容灾和备份。
- 产品版本迭代的过程要自动化且无感知,服务的部署发布复杂度不能超过旧架构。
带着这两点要求,我们来思考原始的服务部署究竟有哪些问题,以及我们可以从哪些角度做出改进。
服务运维模式的进化
0. 石器时代
让一个后台服务最快开发上线的方式,不外乎直接在物理机服务器上进行服务部署,代码变更以及服务运维全程在该服务器上进行。这也是最常见的服务部署方式,需要对服务做任何变更及版本升级时,都需要登录到服务器去操作文件内容,重启服务。在多个服务器提供负载均衡的情况下,这样的操作需要进行多次。
优化方案当然是有的,我们可以通过 git 仓库来管理版本,通过编写 shell 脚本来批量修改与重启。但无论如何这种直接操作服务器代码内容的方式都是十分危险的(删库跑路警告)。
另外,物理机不可避免的受到老化的影响,需要裁撤换新,那么无论新机器与旧机器有多么相似,架构的不同,系统版本的不同,还有一些原有系统中一些魔改的操作,都会让服务的迁移变得极为困难,有时候由于系统核心依赖的缺失而进行的迁移,其难度不亚于重写。我们需要一个与承载环境完全无关的服务来实现一处编写,随处部署的能力。
而这,其实就是 docker 的容器化思路。
1. 青铜时代

容器技术提供的是操作系统级别的进程隔离,可以让服务跑在完全隔离的环境下,无视物理机自身属性,妈妈再也不用考虑我的环境的兼容性问题啦。
在 大型前端项目 DevOps 沉思录 —— CI 篇 中我曾简单介绍过,想要维持产物->制品服务的不可变特性,采用 docker 容器的方式包裹制品服务或许是一个最佳实践。
业务在执行前端源码编译后,进一步将产物放入制品服务的指定目录中,并构建为 Docker 镜像。之后对于任何架构的服务器,只需要拥有 docker 环境,则下载该镜像后一定能运行起来提供完全相同的服务,实现无视宿主机环境的 imutable 部署。
而最简接入的方式也很简单,只需要在项目根目录下增加 Dockerfile 的文件编写即可。
# 安装完整依赖并构建产物
FROM node:14 AS build
WORKDIR /app
COPY package*.json /app/
RUN ["npm", "install"]
COPY . /app/
RUN npm run build
当然优化的方式有很多,具体可以参考我的 NodeJS 服务 Docker 镜像极致优化指北
2. 蒸汽时代

我们的实际服务中,仅靠一个单容器可能不足以支撑所有的应用场景。拿 Web 的场景来说,我们可能会需要一个 redis 服务来做缓存优化,需要消息队列来实现与多后端服务的数据拉取。
这些服务并不是完全独立的,例如接口服务和数据库服务,它们需要共享同一个网络栈,挂载同一个存储卷。我们暂且将这样一个有关联依赖关系的容器集称为Pod。
想要将这样一个Pod作为逻辑整体来进行管理,就需要一个容器组织框架了。市面上的容器管理框架有几种,最典型的就是 docker-compose 了,它能很好的组织多个容器间的依赖关系,做到多依赖服务的批量部署。
常见的 docker-compose 配置形式如下,仅需声明所需的端口、环境以及依赖,即可通过 docker-compose up 一键启动,十分便利。
version: '3.4'
services:
webserver:
image: synccheng/webserver
environment:
- ConnectionString=sqlserver
expose:
- "3306"
ports:
- "8000:80"
depends_on:
- sqlserver
sqlserver:
image: synccheng/sqlserver
environment:
- PASSWORD=[PLACEHOLDER]
expose:
- "3306"
ports:
- "5000:3306"
3. 电气时代
Pod概念的提出,解决了容器之间的关联依赖关系、共享资源等问题。但对于多个Pod的管理,其实也有同样的问题需要解决。例如公共服务Pod与单个业务服务Pod之间也存在关联关系。
关联Pod的生命周期需要进行统一管理调度。例如当版本更新,容器需要销毁重建时,公共服务一定是最先启动,最后销毁的,这样才能保证业务层依赖服务的稳定。
这里根据实际需求的不同,管理调度策略有很多,例如在当前最流行的容器编排引擎 Kubernetes 中,就分为 Deployment、StatefulSet、DaemonSet、Replication 等多种。它们出现的目的,就是解决多Pod间的生命周期管理问题。保证多服务更新或销毁时整体的稳定性。
当然,Kubernetes 提供的能力远不止于此,作为编排引擎,它能够实现服务的自动化部署、设计多Pod的负载均衡、实现动态扩缩容(HPA),等等。基于镜像构建的 imutable 特性,在资源足够的情况下,Kubernetes 能提供近乎无限的容灾和备份能力。
4. 信息时代
我们在 Server 的电气时代中,已经近乎完美实现了之前所要求的第一点:服务的绝对可靠。不过代价是什么呢?增加了大量的复杂度。因此这里需要一名熟悉整套流程的运维人员负责服务的维护和升级,同时他还得熟悉前端的部署流程及发布情况。这样一个角色在哪个公司恐怕都是较为稀缺的。
此时我们可以更进一步思考,如何实现要求的第二点,即在不增加前端同学的理解成本下,无感知地走这一套流程发布新版本,根据该制品的发布所处的不同环境或用途,自动配置好服务所需的各项容灾能力。这时,就轮到基础架构自动化编排工具————Terraform 出场了。
Terraform 充分利用了 Infrastructure as Code, 基础架构即代码的思想,以声明的方式,在配置文件中指定不同资源组中云上硬件资源的分配与管理。
terraform {
required_providers {
aws = {
source = "aws.amazon.com/xxx"
}
}
backend "http" {}
}
# 配置 provider
provider "aws" {
version = "1.0.0"
}
# 生成资源组
resource "aws_resource_group" "deployment" {
metadata {
name = "duang"
namespace = "duang-workspace"
}
spec {
container {...}
volume {...}
...
}
}
至此,服务从服务到软硬件的运维配置自动化链路就已全部串联起来。结合之前介绍的 DevOps 持续集成流水线实践文章,业务开发者就能仅通过 push 业务代码的情况下,自动搭建起来一套运维完备的环境了。
Dockerized Web Server 的概念
一个云原生的服务架构的理论基础有了,接下来我们可以看看,这样一套架构该如何运用在前端开发的部署场景中。
我们可以将一次前端编译构建的产物分成两个部分,入口文件和资源文件。其中,资源文件是静态的,可以加入 hash 之后直接存放在云存储中做持久化存储,并提供 CDN 进行加速。
而入口文件是随着版本动态更新的,客户端访问时,仅需要找到正确版本的入口文件,则可以拉取到全部的资源文件,获取完整内容。而由于各级缓存的存在,如何让用户及时请求到正确版本的入口文件,一直是前端的一大痛点。
基于上面对云原生服务模式的介绍,我们知道,需要给业务的每一个前端版本制作一个不可变的服务镜像,在最基本的情况下,业务只需要自己编写一个转发服务镜像,设置好路由规则,并在指定目录位置存放好编译构建出来的入口 HTML 文件即可。
这样一来,每一个版本都是一个独立的服务,这样想请求到特定版本的话,向特定的容器发送请求即可。那么每一个提供版本入口的服务就可以称其为最简形式的Dockerized Web Server(下简称 DWS )。
此时的项目构建路径如下图所示:
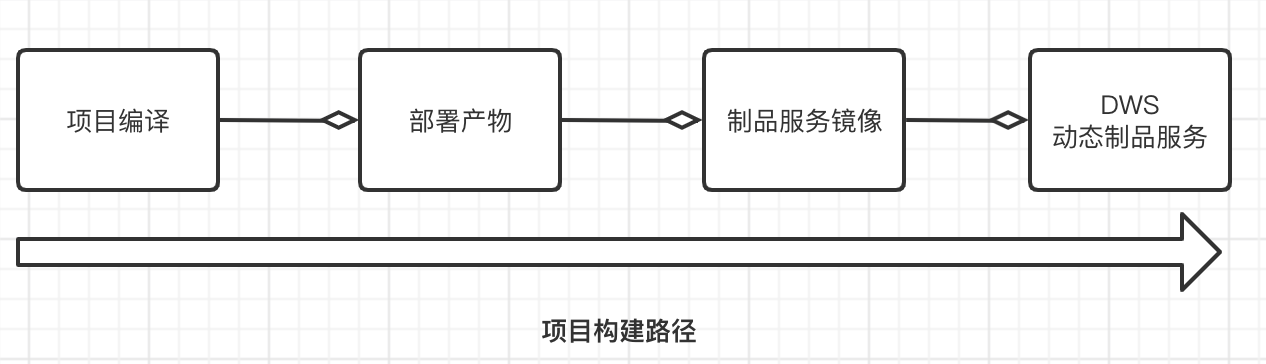
通过上述的结构设计,我们可以发现,这种服务能力本身是与业务无关的,可以统一建立构建模型,实现分布式部署。业务甚至都不需要了解和编写 dockerfile,仅需要接入统一的 DWS 框架,并将构建的产物移动到镜像内,即可借助流水线,自动完成一个 DWS 的打包与部署。
扩展前端能力边界
一些同学可能会疑惑,如果只是给 HTML 这一个入口文件,制作成镜像服务并实现云原生部署,规划一套这么重的方案来承载有些大费周章了。这是将前端的产物默认为静态文件这种简单的形式来考虑的。事实上现代前端所需要涉足的能力远不止于此。
举个栗子,大家都比较熟悉的 SSR。通常来说,涉及到 SSR 功能的页面都会起一个后台服务(通常是熟悉的 node 服务)来完成权限的判断、后台数据的拉取、HTML 代码片段的拼接等等操作,最后直接返回给客户端一个渲染好的首屏完整页面,以此来提高首屏速度。那么实际上,提供这个能力的后台服务其实就是 DWS 里动态的一种表现形式,可以交由 DWS 本地承载并实现。
对于不同的前端项目,除去用来做数据直出的 SSR,还有更多的需要运行时动态判断的功能存在。例如业务想在获取 HTML 之前,做一些数据的预处理,注入到 HTML 里,改变 HTML 内容,比如 A/B Test 中,设置对某个 feature 的开关;又例如,请求时根据权限判断来提前预渲染某个局部元素;甚至能够根据请求路由或参数的不同,返回不同的文件,在同一版本内起到网关的作用,等等。
这些功能以往都是由请求链路上多级的后台服务来分别注入,或是在首屏结束之后,由客户端向各个接口发起 ajax 请求,获取到相应的权限与状态后,去改变页面展示。
很显然,既然 DWS 能够直接与后台数据交互,且通信效率较高,又能直接从本地拿到正确版本的入口文件,那么上述的这些能力完全可以整合到同一个服务内去处理,最后一步到位地返回一个最终的服务端渲染页面。
这样的行为扩展了前端项目的能力边界,将前端开发的交付内容,从传统的 web 网页渲染转变到了整个网页渲染服务的开发与维护。这就是所谓的前端制品即服务。
前端制品的微服务架构
接受了前端制品即服务后,对于前端来说,每个迭代版本需要交付和维护的内容就从普通的 HTML 文件转移到了 DWS 这个动态制品服务中。
而生成的 DWS 作为请求链路的终点,其在请求链路中的位置如下图所示:
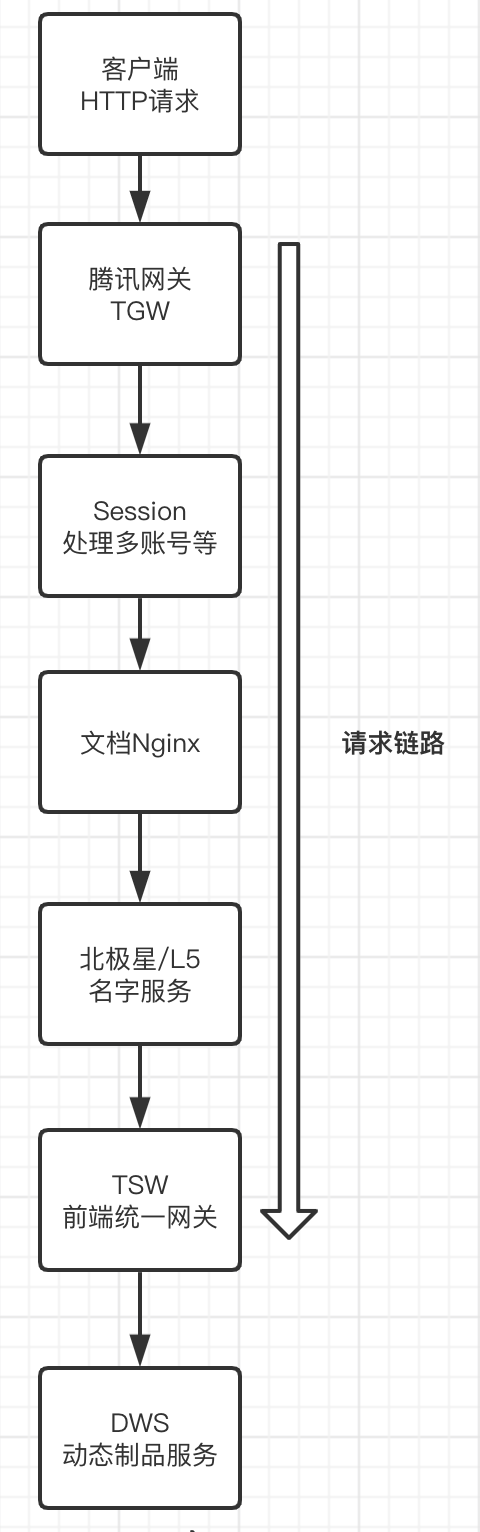
借助流水线,我们可以为每个项目的每一次构建都生成一个不可变的服务镜像,并随时随地部署为容器提供服务。当业务涉及到多个前端项目时,网关可以通过路由或用户特征,将流量请求到相应项目的容器中提供服务,这样就实现了前端多项目场景下的微服务架构。
这样的架构好处在于,项目的不同版本可以共存,不同的项目之间可以任意组装,生成独立的环境副本,不需要另起一个代理服务做转发。
我们可以为不同类型的请求设置一个环境 id,仅环境 id 一致的各项目服务将被响应,对未生成此环境 id 的项目将由该项目的兜底服务响应。这样,我们仅通过一个环境 id,即可串联出来一整套环境。
我们可以任意拼装各个项目的各个版本,任意生成全新的联调测试环境。而这一过程不需要任何代理,也不触发任何部署,仅需绑定相同的 envid 即可实现。
灰度发布环境本质上也是一个特殊的测试环境,因此在环境的实现上也是完全一致的。当然,灰度环境为了确定流量的环境 id,其灰度策略会比较复杂,这里与本文的介绍无关,这一 part 我先挖个坑,在之后的持续部署相关文章中再来讲述。
DWS 服务版本控制及服务能力插件化
之前我们提到,有许多能力都可以集成到DWS中来统一调用。但作为一项通用服务框架,如果不加限制的由业务方一味地往里面加功能,必定会给服务带来很大的隐患。
不同业务的需求可能不同,非通用能力的加入,需要做兼容处理的情况将会非常复杂,服务的响应时间也可能因此延长。另外,业务直接修改通用服务的代码进行升级是一个很危险的行为,就算业务自身调试通过了,也可能会对其他业务造成不可预知的影响。
为了解决这一问题,我们提出两点改进思路。
第一点是给服务加上版本控制。业务使用时,必须指定好特定版本的 DWS 服务版本,这样就能保证业务代码不变的情况下,打包出来的动态制品服务具有一致性,不受 DWS 更新影响。在动态制品服务需要进行更新时,在业务代码仓库里也能有所体现,保证业务方能够被感知到,便于版本审计。
第二点是将能力开放出来,将每一个功能特性都视为 DWS 的一个能力插件,当且仅当业务需要时,才会被引入和执行。
参考 koa 实现中间件的思路,我们也可以将插件设计为洋葱模型,洋葱模型的最外层,即请求的最外层变量封装以及响应的最终形态由 DWS 内部统一控制,其余对请求与响应的任何改造都可以交由插件来修改。

插件的实现方法找到了后,现在的难点来到了,业务在接入 DWS 时,如何将所需的插件注入进去。
为了实现逻辑解耦和易于插拔这两点,我们采用声明式注册的方式。
在业务的配置文件中告知 DWS 所需插件的引用入口位置,可以为远端,也可以为本地,在镜像构建时,将读取配置文件,查询下载所有的插件,打包到 DWS 内,以洋葱模型规定的顺序依次调用。
对于存放至远端的插件,我们一般视为可以给其他业务通用的能力,可以统一收归到一处,以类似于插件市场的形式提供给业务方查阅取用,同时,通用插件应与 DWS 核心服务一样,也拥有版本控制能力,保证插件能力修改时业务方能够被感知。
一般来说,通用插件会根据具体需求的不同,在逻辑有一些变更,此时需要调用方根据自身项目情况传入一些特定参数。为了解决这一点,我们可以将插件做成工厂模式,接收配置文件中的 options 参数,返回出符合要求的插件,从而提升通用插件的灵活性。
如此一来,插件的配置文件声明格式就确定下来了。
"version": "1.0.0",
......
"middlewares": [
{
"name": "local-plugin",
"path": "./local-plugins/index.js",
"options": {}
},
{
"name": "@tencent/remote-plugin",
"version": "v1.0.0",
"options": {}
}
]
对于本地插件的编写,业务方自己拥有完全的控制能力,完全不需要更改动到 DWS 服务本身。通过插件的形式,前端在不用建立任何额外服务端的情况下,也能实现一些原先需要搭建服务端才能处理的功能了,可以基于此做很多有趣的扩展。
结语
本文介绍了云原生架构在增强服务稳定性以及自动化能力上的优势,并结合前端项目部署特点做出了一些通用性的实践。当然,这套体系还远不够成熟,但它的想象空间是十分巨大的,它拓展了前端的能力边界,在不需要维护新的后台服务的情况下,得以对产物进行服务端预处理。
这个坑很大,但也很有意思,对此感兴趣的小伙伴欢迎参与进来一起探讨,在云原生的大环境下,我们前端还能做些什么。