大型前端项目 DevOps 沉思录 -- CD 篇
提示
DevOps一词源于Development 和 Operations 的组合,即将软件交付过程中开发与测试运维的环节通过工具链打通,并通过自动化的测试与监控,减少团队的时间损耗,更加高效稳定地交付制品。
本篇文章将着重探讨 DevOps 在 持续部署阶段 需要提供的能力,介绍大型项目应该如何稳定并高频率的迭代项目版本。
在系列的 上一篇文章 中,我们详细介绍了腾讯文档前端在 DevOps 的 持续集成阶段 所作出的实践与思考,介绍了在 CI 阶段项目工作流的设计及流水线的优化思路。
本次我们将探讨 DevOps 在 持续部署阶段 需要提供的能力,介绍大型项目应该如何稳定并高频率的迭代项目版本。
正确认识持续部署
我们在为一个项目搭建自动化流水线时,通常会将项目的代码检查、自动化测试、代码编译、部署环境等等环节全部放入同一条流水线,因为许多时候,这都是一条逻辑清晰且稳定的链路,能够确保发布产物一定完成了全部的自动化检查。
常见的项目流水线应该如下图所示,是一条大而全的串行链路:

由于这样的 CI/CD 流水线经常被各类文章列为最佳实践,于是很多时候,我们很容易将 CI/CD 流程混为一谈,甚至将其等同于构建 DevOps 流水线的全流程,这种认知其实是不对的。
持续部署(Continuous deployment,缩写为 CD),是一种软件工程方法,意指在软件开发流程中,以自动化方式,频繁而且持续性的,将软件部署到生产环境中,使软件产品能够快速的发展。
与上一章介绍的持续集成不同,持续部署更多的是侧重在已经生成的制品如何高频且低风险的自动部署到各种测试、灰度与生产环境的。想要做到高频与稳定,我们需要彻底将持续部署环节从持续集成环节中分离出来,形成独立的流水线。
解耦 CI 与 CD 环节
为何要将 CD 从 CI 中分离
一个项目在发展成熟的过程中,代码将逐渐变得庞大且复杂,项目编译、代码检查和自动化测试的时间将不可避免的越变越长。但与此同时,高频部署与版本切换对于一个自动化成熟的项目来说也是一个必选项。尽管在持续集成阶段,我们可以用上篇文章介绍过的次级构建等方法来减少从代码推送到制品生成之间的耗时,但距离我们期望的快速版本切换来说仍然杯水车薪。
这个问题在现网出现致命故障回滚时暴露的尤为明显。以我们团队项目之前的实践为例,在回滚版本时,实质上是将打过git tag的上一版本节点抽离出分支进行一次提交,等待其执行了完整的 CI/CD 流程后在源站服务器上更新我们的 HTML 完成更新。也就是说,我们的回滚操作所需的准备时间几乎是和发布一个新版本同样长。这对于一个用户量较大的成熟项目来说是不可接受的。
其实,我们是被长时间的自动化构建思维带入了误区,认为发布流程不经过 CI 验证过就不是一个合格的产物。想要实现瞬间回滚其实很简单,我们只需要记录之前版本的发布产物,在需要回滚时直接进入服务器将之前记录过的某一版本发布到源站服务器即可。
但是这种由人工来手动选择文件并拷贝覆盖到服务器的方式显然容易出错,我们还是应该利用流水线的能力来实现这一功能,而这就是与 持续集成 分离后,持续部署 流水线的其中一个能力。
DevOps中所谓持续,是指每完成一个完整的部分,就向下个环节推进,如果发现问题可以在当前环节内调整和重试,并不会影响其他环节。以回滚为例,同一个制品已经通过了持续集成的测试并完成交付后,就不应该再对其进行第二次 CI 环节了,而只需重新执行持续部署流程即可,而通常,持续部署的环境切换效率是极高的,这就是将 CI 与 CD 环节解耦的意义。
如何分离
实现思路上,我们首先要解决的,是找到一个合适的位置存储每次 CI 构建生成的产物。
在信息系统的设计理论中,存放唯一可信信息的地方被称为 SSOT(Single source of truth)与 SVOT(Single version of truth),这样能确保我们获取的信息是真实可信的,具有权威性的。
这里的可信包含两个方面,质量与安全。
可信质量:指开发过程中的代码质量、测试通过率、审批结果、合规性、所属人等。
可信安全:指开发过程中的代码安全风险、外部依赖安全风险、动态应用安全风险等。
每一个通过 CI 生成的制品被存入镜像仓库后,会将存放位置、代码版本、CI 各质量流程完成结果等等信息,作为一条记录存放在 SSOT 中,而可信这一概念在制品信息中的表现,则是可以通过在该条记录中添加标签或索引来实现。
于是我们可以得到大致这样的一条记录,表明了制品的生成时间,镜像地址,仓库分支来源,质量校验结果等等一系列的信息。制品版本的对应关系一目了然。
于是,在新思路的引导下,我们重新定义了 CI 流程的终点:
在经过 CI 流水线的各流程质量验证后,生成制品并存至制品仓库,同时通过各流程的检验结果为该制品设置可信标签,一并存入 SSOT 中,生成一个新的可信版本。

而这条版本信息,也成为了 CD 的起点。需要部署时,只需根据标签或索引信息筛选出符合要求的最新制品信息,即可找到对应制品,部署该版本。
由于制品本身已完成编译且质量合格,因此能直接安全的部署在生产环境中。从而极大的缩短了部署流程的时间。
该过程不仅作用在新版本发布中,热修复、灰度部署、回滚等产品常见的特殊部署场景全都可以通过 SSOT 的查询来找到可信制品来跳过 CI 步骤,仅需完成审批,就能全自动发布。
前端制品的交付形态
我们接下来要解决解耦过程中的另一个核心问题:我们向 SSOT 交付产物的形态是什么?
众所周知,前端的版本生成产物无非是 HTML、JS、CSS 等几类。我们可以简单地将前端产物划分为两类:静态资源类文件与入口类文件。
静态资源类文件,即如 CSS、JS 之类,处置起来较为简单,仅需带上 hash 后存放于云存储中作为源站资源,并定期同步给 CDN 即可。
重点在于,我们该如何交付每个版本生成的入口类产物。这个才是在持续部署过程中真正需要替换升级的部分。

对于绝大多数项目来说,很容易将这一部分想的过于简单。例如直接将入口类产物封装为文件夹,统一放到某处进行存储,之后通过改变网关的路由指向(可能有些项目会利用外部的配置系统,映射路由指向,网关通过请求来动态的获取入口文件指向),更新并重定向到新版本入口文件。
但实际上,这样的方式存在着一些隐患,我列举几点:
直接将产物以文件形式的部署方式,其本质上是向一个或多个服务器进行产物文件上传。本质上是对产物的移动与粘贴,不方便对产物的更新历史进行追溯,无法做更精细化的版本管理。
以文件夹存放文件来分隔各版本产物,这样的版本组织结构过于松散。产物文件直接存储在服务器上,有被人为篡改的风险。且一旦在产物中执行修改操作能立即改变现网内容,并且这一过程不会经过任何审计,是十分危险的。
数据源的存储位置问题。如果数据源存储于网关本地,或是挂载硬盘,那么就需要考虑冗余备份的问题,并且数据出现故障或者需要迁移时,由于历史版本全部存于一处,数据量巨大,恢复起来会比较困难。而如果存储位置存放在云存储之类的位置,那么势必会用到额外的配置系统,网关通过来完成路由映射。而此时配置系统也成为了关键服务,如果不能保证稳定性,整个网关将会完全崩溃。
总结一下,上面提到的问题有两个核心点,一是需要一个更 immutable 的方案,保证每一版本的制品能被封装为一个不可变整体,而是需要保证每一个版本都能不受外部环境依赖。
根据这样的特性描述,我们很容易想到 Docker 镜像。那么,前端能否利用以及如何利用好 Docker 这一形态作为交付制品呢?
生产能被云原生调度的合格制品
在 CI 篇 中曾提到,由于前端的特殊性,对于静态资源,如 js、css 等文件的网络加载时间较为敏感,同时 HTTP 请求也具备多级缓存的能力,因此这些静态资源放于源站并同步给 CDN 仍然为最优解。于是需要上云的产物便只关联用户的首次请求产物,也即 HTML 了。
一些同学可能会觉得,如果只是 HTML 这一个文件,完全不需要以一个这么重的方案来承载。这其实还是将前端的产物设想为文件这种简单的形式来考虑的。
实际上,对于稍复杂的前端项目来说,用户接收到的 HTML 返回很多都是运行时动态生成的,例如功能开关、灰度、渠道特性、SSR、ABTest 等等功能,这都是根据用户当前请求,即时地返回不同的 HTML。换言之,这里的 HTML 生成器其实是一个 Web 资源服务。
介绍到这里,我们会发现,这里的 Web Service 实际上是一个前端动态化能力的 BFF (Backend For Frontend) 层,为前端增加了一个承载动态化渲染逻辑的位置,从而取代掉一般项目中服务端渲染的服务层。考虑到前端同学的习惯以及相关功能的生态兼容,该 Web Service 同样可以使用 NodeJS 来承载。
因此,前端每次发布一个版本,就会形成一个新的微服务,用于提供服务端直出能力。这么想来,前端服务通过云原生的方式,对制品镜像进行管理是不是就合理多了?
当然,云原生的特性带给这个 BFF 层的特殊玩法可远不止于此。由于与持续部署流程的行文关联不大,这里我继续埋个坑,之后有空了再来介绍云原生下的 BFF 层应该如何设计。
前端制品的云原生部署
自动交付与部署
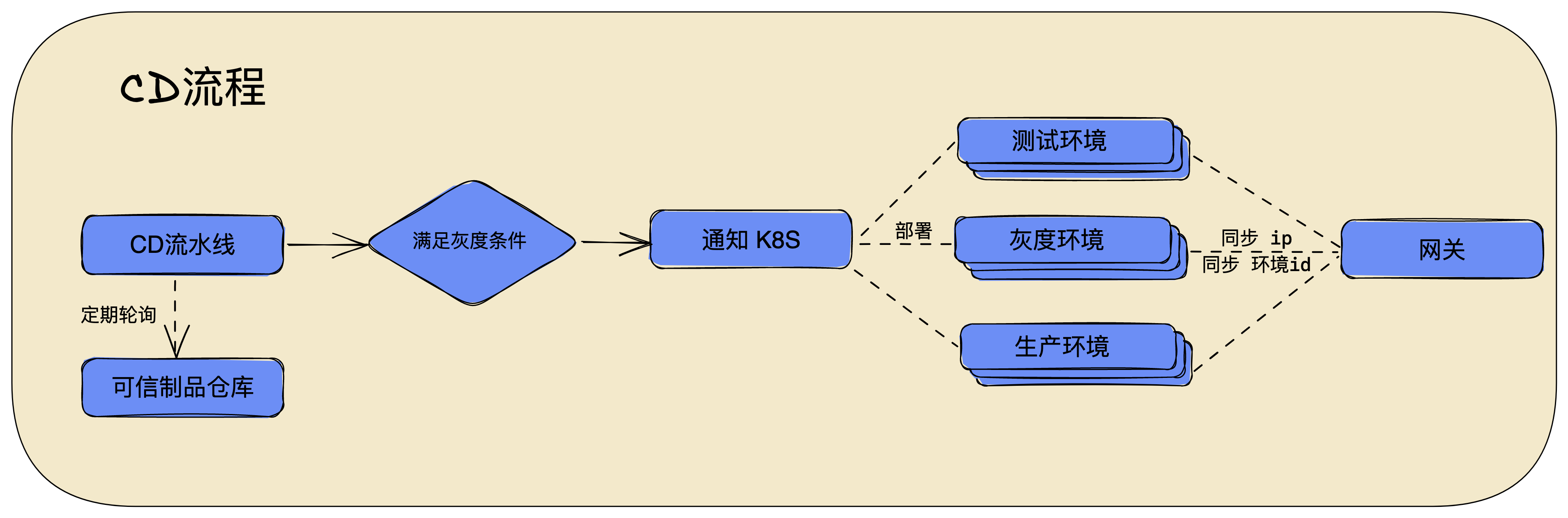
在合格的镜像版本存入 SSOT 之后,我们要对现有的服务进行一个更新。在这里,流水线可以定期向 SSOT 进行轮询,看是否有新的符合要求的产物被生成出来,若有则触发部署流程,更新容器。这里的情况有两种,建立新容器还是更新已有容器。
为了实现自动区分部署目的,我们决定利用 git 的分支名特征。在 gitOps 管理的项目中,分支名规范了代码的目标环境。例如 feature/xx 和 develop 分支属于测试环境,master 和 release/xxx 分支属于生产环境,当然在分支规范上可以自定义。
通过判断分支名,我们即可知晓更新行为。例如,被判断为测试环境的镜像部署时,满足同名分支环境仅保留一个的原则进行新建或更新。当被判断为生产环境的制品镜像生成时,进行制品各项审核参数校验,全部要求通过后开始推送到预发布环境等待进行灰度流转。
每个版本的 BFF 服务制品,通过独立打包为镜像的方式,交由 K8S 统一调度。为了按需分配不同环境下服务的硬件配置,我们参考了谷歌 GKE 的实践,使用了 Terraform 做声明式 K8S 配置管理。这样通过流水线,我们得以合理的分配各环境所占用的硬件资源。
前端请求的调度
在部署完成后,用户的访问请求该如何通过网关分配到目标环境中呢?
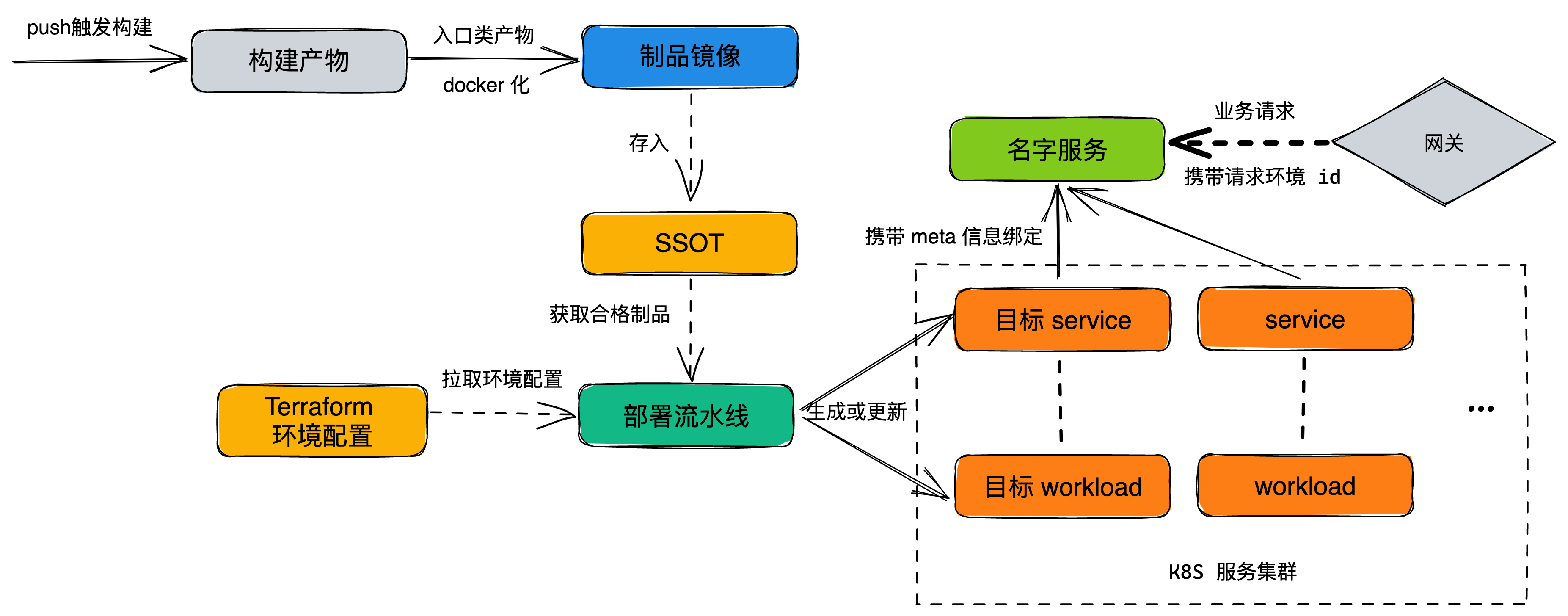
之前提到,我们通过 Terraform 进行了容器编排。在部署时,通过将 SSOT 中获取到的分支或灰度版本等信息等作为 metadata,通过 K8S Service 绑定关联到对应的名字服务中。
在用户请求时,可以通过号码包分配或者手动设置 cookie 等方式设置目标版本,作为 metadata 发送给名字服务,从而获取到正确的版本入口。
那么这样一套服务化的好处在哪里呢?
我们可以看到,由于每个项目进行的每次构建都会部署出一个全新的服务,在链路层级上与后台微服务是平级的。
这样一来,业务的前端与后端的多个制品可以通过请求参数进行随意组合,通过请求头中携带相同的 metadata 信息串联起来,形成一个全新的环境,而该环境的生成本身无需任何额外的部署操作。

这极大便利了前后端,甚至是多个前端之间的联调。我们无需搭建一个新的开发环境同时修改代码,甚至各服务项目之间不需要知道其他服务的存在就能实现联调能力。
同理,测试、预发布、发布环境在请求上只有参数上的不同,无需配置额外的 host 或入口。从而解决了联调与灰度环境配置及测试的难题。
制定平滑的灰度策略
产品在迭代过程中,不可避免的需要对版本进行升级,进行代码修改,而修改则意味着风险。因此,只要不改代码就不会有风险。(划掉) 因此,我们需要灰度机制来降低风险带来的影响范围。其中业界最普遍的实现方式便是大名鼎鼎的金丝雀 (canary) 发布。
冷知识 -- 金丝雀发布的名称由来。
17 世纪,英国矿井工人发现,金丝雀对瓦斯这种气体十分敏感。空气中哪怕有极其微量的瓦斯,金丝雀也会停止歌唱;
当瓦斯含量超过一定限度时,虽然鲁钝的人类毫无察觉,金丝雀却早已毒发身亡。
当时在采矿设备相对简陋的条件下,工人们每次下井都会带上一只金丝雀作为瓦斯检测指标,以便在危险状况下紧急撤离。
传统的金丝雀发布为:选用少量的固定数量的服务器作为金丝雀部署机,将一些特定的灰度用户的流量导入到该台机器上测试新版本功能,无误后再进行全量发布。
这里会有两个地方不够灵活,一是金丝雀部署机的机器数量较为固定,扩缩容较为困难,因此要求灰度用户的访问流量峰值必须维持在一定水平,流量少了浪费机器,多了顶不住。二是灰度用户规则是写死的,例如 QQ 的灰度用户方案是以用户 id 后两位来判断是否进入灰度的,不够随机,在某些场景下有可能无法反映真实情况。
而这就是为什么我们花了大力气将制品镜像化,进行云原生部署的主要原因了。
由于 Docker 镜像启动的服务完全一致的特性,再通过引入 K8S 进行容器管理,以上这两个问题都迎刃而解了。HPA(Horizontal Pod Autoscaler)能力,通过流量或硬件占用率等策略实现了自动扩缩容。而滚动发布、间隔发布的策略则解决了升级的平滑度,我们不再需要定义具体哪些用户,具体多少百分比进入灰度。在流水线的帮助下,一切都是缓慢且稳定进行着的。
当然,这样的灰度策略还远不够极限,为了对特性的开关控制进行更快速的响应,有时我们会增加运行时的特性灰度能力,不过这就涉及到 CE(持续实验)环节了,这块的知识我们先按下不表,下次有机会再开新坑。
结语
本文介绍了在云原生的浪潮下,大型前端项目在持续部署环节做出的一些尝试。简要介绍了包括制品可靠性、部署可靠性、灰度可靠性的自动化流程处理思路。
随着互联网服务的发达,为了产品的高可用,前端项目在站点可靠性(Site Reliability)上的要求也正变得越来越高。依赖云服务的弹性能力,利用流水线对镜像进行自动化部署,进而解放运维人力,实乃降本增效的一剂良药。
参考资料
- 《持续交付 2.0》—— 乔梁 著
- Google Anthos 混合云 Devops 实践
- 蓝绿发布、滚动发布、灰度发布等部署方案对比与总结