从零推导指数估值模型 —— 一个三因子打分系统的设计思路
提示
"估值"是投资领域中最常被提及却最容易被误解的概念之一。本文将从第一性原理出发,逐步推导出一个实用的三因子估值打分系统(PE 百分位 + PB 百分位 + 股权风险溢价),详细剖析每个因子的数学含义与相关性,并讨论为什么看似合理的"五因子模型"在实践中反而不如更精简的三因子模型。
估值到底在度量什么
当我们说一个指数"被低估"了,这句话到底是什么意思?
很多人的第一反应是"PE 低就是低估"——市盈率 10 倍比 30 倍便宜,所以 PE 低的时候买入。这个直觉方向没错,但过于粗糙。同一个指数,在不同的历史时期,"合理"的 PE 是不一样的。沪深 300 在 2015 年牛市顶峰的 PE 是 18 倍,而在 2018 年底部是 10 倍——但你不能说 15 倍就一定是"贵"的,因为 2010 年时它的 PE 中位数在 14 倍左右。
所以,我们需要的不是绝对值的判断,而是相对于自身历史的位置判断。这就引出了估值模型的第一个核心概念:历史百分位。
一个指数当前的 PE 百分位 = 30%,意思是在过去 N 年的交易日中,有 30% 的时间 PE 比现在更低。换言之,当前估值处于历史偏低的位置。
这看起来很简单对不对?但如果我们只靠一个 PE 百分位就能做投资决策,那量化投资也太容易了。实际上,单一指标存在很多盲区,而如何选择和组合多个指标,才是估值模型设计中最值得深入思考的问题。
从单因子到多因子:不是越多越好
在设计估值模型时,一个自然的想法是:既然一个指标不够,那就多加几个。PE 百分位不够就加 PB 百分位,PB 还不够就加股息率、股权风险溢价(ERP)、股息-债息利差……指标越多,覆盖越全面,模型越"科学",对吧?
我最初也是这么想的。在第一个版本的行业估值系统中,我设计了一个五因子模型:
| 因子 | 含义 |
|---|---|
| PE TTM 百分位 | 市盈率历史分位,反映盈利估值水位 |
| PB 百分位 | 市净率历史分位,反映资产估值水位 |
| 股息率(DY)百分位 | 股息率历史分位,反映分红吸引力 |
| 股权风险溢价(ERP) | 盈利收益率 - 国债收益率,反映股票vs债券吸引力 |
| 股息-债息利差(Yield Spread) | 股息率 - 国债收益率,反映分红vs无风险利率 |
五个因子,每个听起来都有独立的经济含义。但当我尝试用数学去检验这些因子之间的关系时,问题就暴露了。
因子正交性分析:五个因子只有两个半维度
我们来做一个简单的数学推导,看看这五个因子之间到底是什么关系。
先列出几个基本的财务恒等式:
PB = PE × ROE (ROE = 净资产收益率,Return On Equity)
DY = 每股派息率 / PE (DY = Dividend Yield,股息率,是指每股派息金额占每股价格的比例)
ERP = 1/PE - Rf (Rf = 无风险利率,即国债收益率,risk-free interest rate)
Yield Spread = DY - Rf = 每股派息率/PE - Rf (Yield Spread 收益率差,这里指该指数的收益率与国债的收益率差)
这几个等式揭示了一个关键事实:这五个因子并不是五个独立的维度。
PE 和 PB 之间通过 ROE 关联。如果一个行业的 ROE 长期稳定(比如银行、公用事业),那么 PE 和 PB 的百分位走势会高度同步。但如果 ROE 波动大(比如周期股在盈利高峰和低谷之间反复横跳),PE 和 PB 就会出现分歧——这也正是 PB 因子存在的价值:它在 PE 失真时提供了另一个锚。
所以 PE 和 PB 可以算作"接近两个独立维度",在 ROE 稳定的行业接近一个维度,在周期行业接近两个。取折中,大约 1.5 个独立维度。
接下来看剩下三个因子:
ERP = 1/PE - Rf。它本质上是 PE 的倒数减去一个外部变量(国债收益率)。其中 1/PE(盈利收益率)完全由 PE 决定,而 Rf 是一个宏观变量,对所有股票都一样。所以 ERP 相对于 PE 引入了大约"半个"新维度——那个半维度就是利率环境的信息。
DY = 每股派息率 / PE。它也是 PE 的变换,多了一个派息率的调节。但对于大多数指数来说,派息率在中短期内变化不大,所以 DY 百分位与 PE 百分位高度相关。
Yield Spread = DY - Rf = 派息率/PE - Rf。这东西和 ERP 的结构几乎一模一样,区别只是用了"派息率/PE"替代了"1/PE"。由于派息率 < 1,Yield Spread 实际上是一个"缩小版的 ERP"。
画一张关系图就更清楚了:
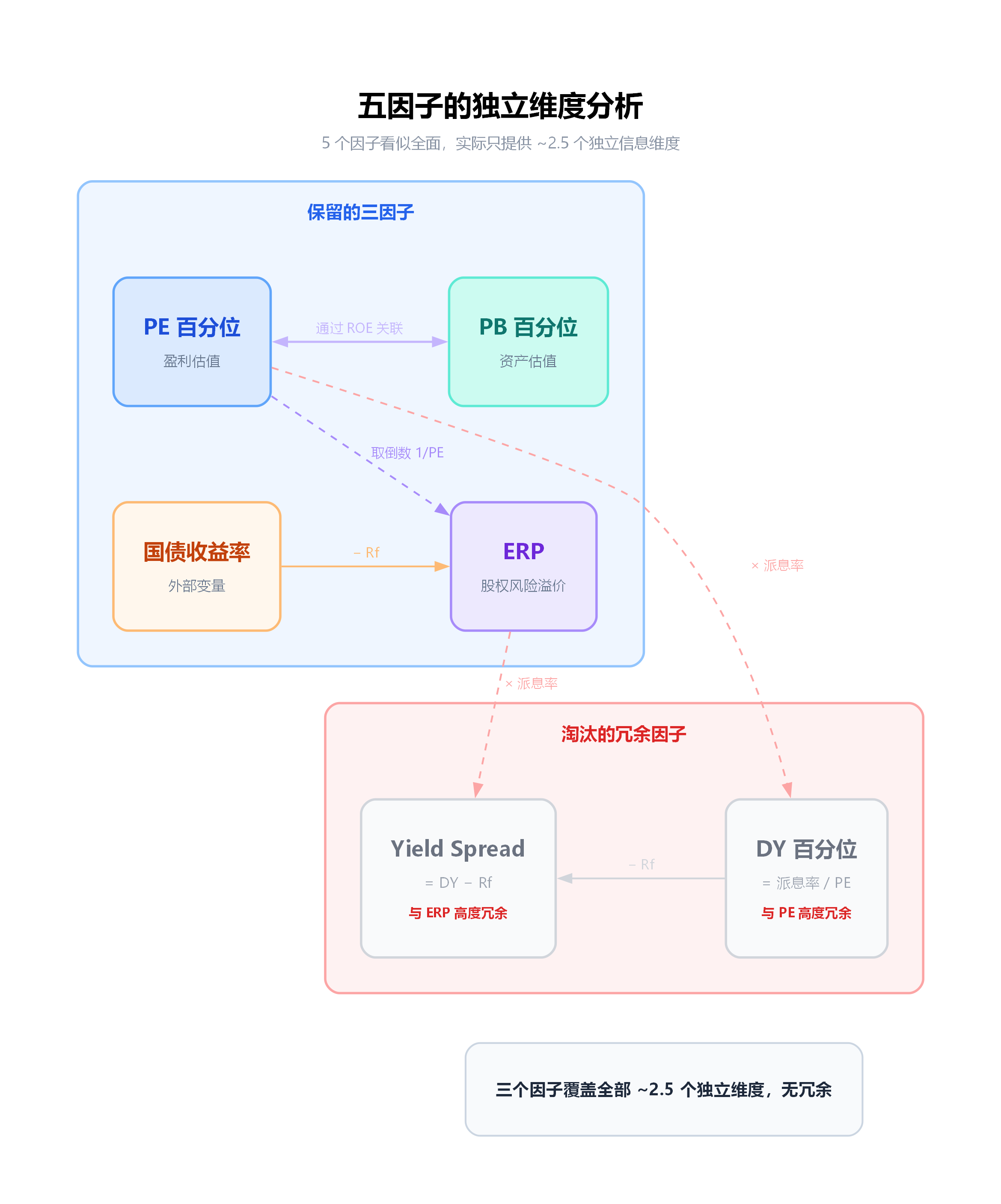
结论:五个因子只提供了大约 2 到 2.5 个独立信息维度。
这意味着如果我们天真地把五个因子都加入模型,看似覆盖面很广,实际上只是在用不同的数学表达反复强调同一件事。更糟糕的是,这种冗余会导致权重分配失真——比如在某些行业配置中,与 PE 相关的因子(PE 百分位 + ERP + DY + Yield Spread)占了总权重的 70% 以上,而真正独立的 PB 维度反而被边缘化了。
三因子模型:选择信息密度最高的组合
既然五个因子有大量冗余,那应该保留哪些?
原则很简单:在每个独立维度上,选择信息密度最高的那个代表。
维度一:盈利估值 → PE TTM 百分位
没有争议。PE 是最直观、最通用的盈利估值指标。它衡量的是"为每一块钱的盈利,市场愿意付多少钱"。PE 百分位把这个绝对值转化为相对位置,消除了不同行业之间的可比性问题。
维度二:资产估值 → PB 百分位
PB 的存在是为了在 PE 失灵时提供补充。什么时候 PE 会失灵?最典型的场景是深度周期行业的 Molodovsky 效应。
举个例子:钢铁行业在行业景气高峰时,利润暴增,PE 反而降到个位数(看起来很"便宜")。但这恰恰是行业最危险的时候——高利润意味着产能即将过剩、价格即将下跌。反过来,在行业最低谷时,利润跌到接近零,PE 飙升到几百倍(看起来很"贵"),但这其实是买入的好时机。
这就是 Molodovsky 效应:PE 在周期股上给出的信号是反的。
而 PB 不受盈利波动的影响(它衡量的是资产价值而非盈利),在周期底部依然能够正确反映资产折价程度。因此,对于深度周期行业(钢铁、煤炭、有色金属等),PB 是比 PE 更可靠的估值锚。
这对模型设计有两个直接的影响:
- 权重倾斜:对于深度周期行业,应该大幅提高 PB 的权重,让 PB 主导估值判断,PE 只作为辅助参考。同时,由于 PE 本身不可靠,依赖 PE 的 ERP(= 1/PE - Rf)也不应参与评分。
- PE 评分取反:深度周期行业的 PE 评分需要反转——
score = 100 - pe_ttm_percentile,百分位越高(盈利越差)反而越有吸引力。
维度三:利率环境 → 股权风险溢价(ERP)
PE 和 PB 百分位都是纯粹的"自我比较"——拿指数当前的估值和自己的历史比。但这忽略了一个关键的外部变量:无风险利率。
同样是 PE = 15 倍(对应盈利收益率 6.67%),在十年期国债收益率 2% 的环境下和 5% 的环境下,含义完全不同。前者意味着股票比债券有 4.67% 的超额收益,后者只有 1.67%。
ERP(Equity Risk Premium)正是捕捉这个维度的最佳指标:
ERP = 盈利收益率 - 无风险利率 = 1/PE - 国债收益率
那为什么不用 Yield Spread(股息-债息利差)来代替 ERP 呢?两个原因:
- 覆盖范围。盈利收益率覆盖了公司的全部盈利(包括留存再投资的部分),而股息率只覆盖分红那一小部分。对于成长型行业(如电子、计算机),很多公司派息率极低甚至不分红,股息率几乎没有参考价值,但盈利收益率依然有效。
- 信息完整性。ERP = 1/PE - Rf,Yield Spread = 派息率/PE - Rf。后者只是前者乘以一个派息率系数。在派息率稳定的前提下,两者高度共线。而 ERP 包含的信息严格多于 Yield Spread。
所以在 ERP 和 Yield Spread 之间,ERP 是更优的选择。而 DY 百分位已经被 PE 百分位大部分覆盖(DY = 派息率/PE),不值得单独占一个因子的位置。
最终,三因子模型的因子选择是:
| 因子 | 独立维度 | 核心信息 |
|---|---|---|
| PE TTM 百分位 | 盈利估值 | 当前盈利定价在历史中的位置 |
| PB 百分位 | 资产估值 | 当前资产折溢价在历史中的位置 |
| ERP | 利率环境 | 股票相对于债券的吸引力 |
三个因子,覆盖了全部 2.5 个独立维度,没有冗余。
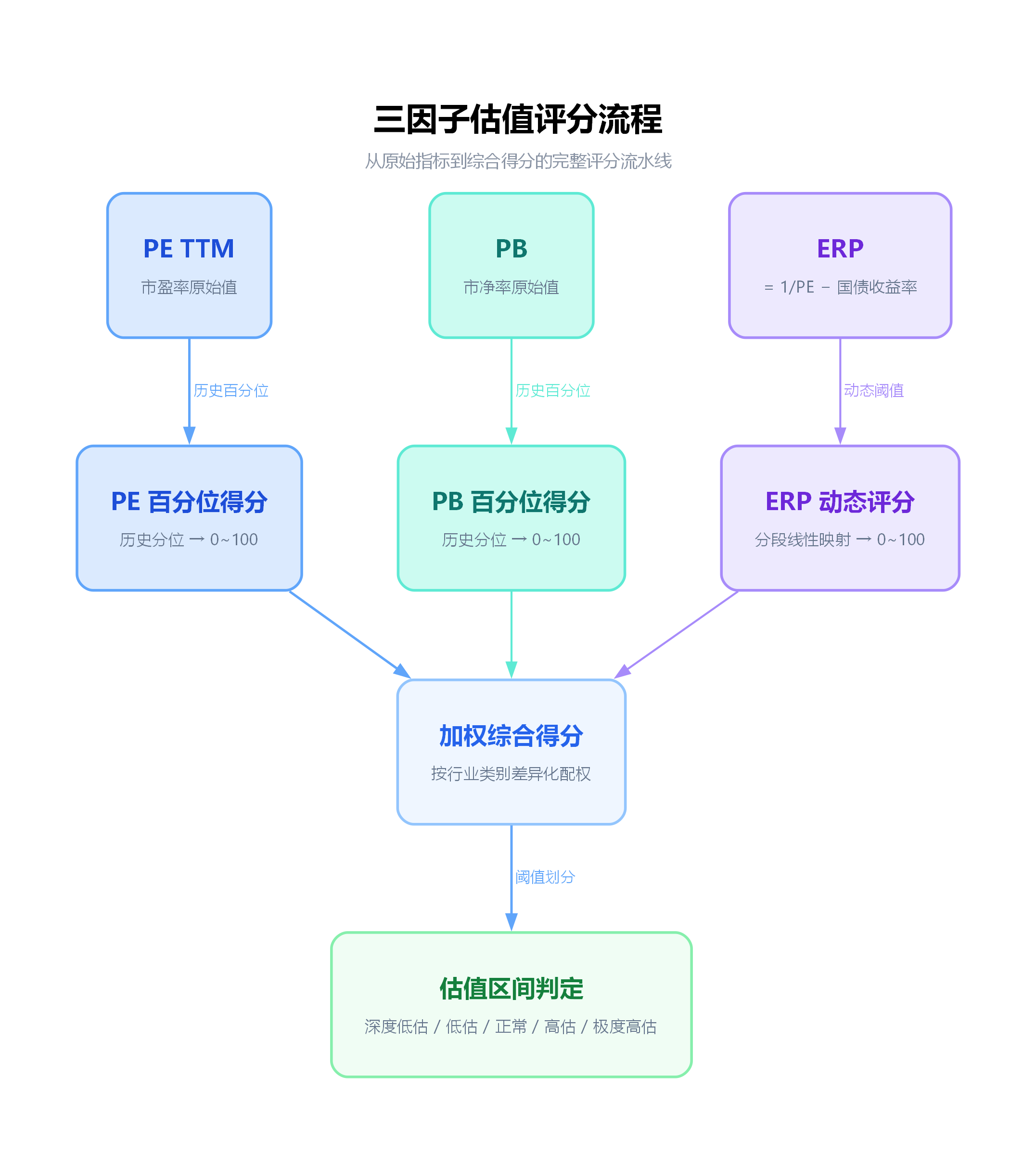
评分映射:从指标值到 0-100 分
确定了因子之后,下一步是把每个因子的原始值映射到一个统一的 0-100 分体系,其中:
- 0 分 = 极度有吸引力(深度低估)
- 100 分 = 极度无吸引力(严重高估)
- 50 分 = 中性
PE 和 PB:百分位即得分
对于百分位类因子,映射非常直接——百分位本身就是得分。PE 百分位 20% → 得分 20(偏低估)。PB 百分位 80% → 得分 80(偏高估)。
但对于深度周期行业,如前文所述,PE 和 PB 的得分都需要取反——百分位越高反而越有吸引力:
if is_deep_cyclical:
pe_score = 100 - pe_percentile
pb_score = 100 - pb_percentile
else:
pe_score = pe_percentile
pb_score = pb_percentile
ERP:分段线性映射
ERP 不是百分位指标,它是一个有明确经济含义的绝对值。我们需要设定一组阈值来定义"什么水平的 ERP 算高,什么算低"。
思路是这样的:根据历史经验,A 股市场的 ERP 大致在 -3% 到 +6% 之间波动。我们可以在这个范围内划分若干档位,每个档位对应一个 0-100 的得分——ERP 越高(股票越有吸引力),得分越低。比如 ERP 超过 6% 时评为 5 分(极度低估),ERP 低于 -3% 时评为 95 分(严重高估)。
相邻档位之间使用线性插值,确保得分变化是平滑连续的:
def map_value_to_score(value, thresholds, default_score=95.0):
"""在相邻阈值之间线性插值,得到连续的得分。"""
if value >= thresholds[0][0]:
return thresholds[0][1]
for i in range(len(thresholds) - 1):
upper_val, upper_score = thresholds[i]
lower_val, lower_score = thresholds[i + 1]
if value >= lower_val:
t = (value - lower_val) / (upper_val - lower_val)
return lower_score + t * (upper_score - lower_score)
return default_score
动态阈值调整
但这里还有一个微妙的问题。上面的 ERP 阈值是基于"历史平均利率环境"设定的。如果无风险利率显著偏离历史均值,固定阈值就会产生系统性偏差。
比如,当 10 年期国债收益率从历史均值 2.8% 下降到 1.5% 时,即使股市估值没变,ERP 也会因为 Rf 下降而机械性升高。如果我们的阈值不跟着调整,模型就会持续发出"低估"信号,而实际上只是利率环境变了。
解决办法是让 ERP 阈值跟随利率环境动态漂移:
def get_dynamic_erp_thresholds(bond_yield, base_thresholds,
baseline_bond_yield, adjustment_rate=0.5):
"""当利率偏离基线时,阈值同向调整。"""
adjustment = (bond_yield - baseline_bond_yield) * adjustment_rate
return [(erp_val + adjustment, score) for erp_val, score in base_thresholds]
这里的 adjustment_rate = 0.5 意味着:国债收益率每偏离基线 1 个百分点,ERP 阈值移动 0.5 个百分点。为什么不是 1:1?因为利率变动对股市估值的影响不是完全线性传导的,0.5 是一个经验性的折中系数。
加权合成:综合得分的计算
每个因子都有了 0-100 分的评分后,综合得分就是加权平均:
def calculate_composite_score(factor_scores, weights):
"""加权计算综合得分。任一因子缺失则拒绝计算。"""
weighted_sum = 0.0
for factor_name, weight in weights.items():
if weight <= 0:
continue
score = factor_scores.get(factor_name)
if score is None:
return None # 严格策略:缺一不可
weighted_sum += score * weight
return round(weighted_sum, 2)
不同类型的行业,三个因子的权重应该有所不同。这背后的逻辑是:不同行业对三个因子的"信任度"不一样。
- 深度周期行业(钢铁、煤炭等):PB 主导,PE 辅助(且取反),不使用 ERP。因为 PE 在周期股上不可靠,ERP = 1/PE - Rf 自然也跟着失真。
- 金融行业(银行、保险等):PB 权重最高(银行的核心是净资产),ERP 也有较高权重(金融股对利率敏感),PE 权重最低。
- 稳定消费(白酒、家电等):PE 权重最高,因为盈利稳定可预测,PE 百分位的信号质量最好。
- 成长行业(电子、计算机等):PE 和 PB 并重,ERP 适度降权——成长股投资者更看重内生增长潜力,利率因素的影响相对次要。
- 防御行业(公用事业、交通运输等):三因子相对均衡,ERP 略高——这类行业现金流稳定,天然具有"类债券"属性,利率变化对其影响显著。
权重的具体数值需要根据各行业特征和历史回测来校准,这里不展开讨论。重要的是理解背后的思路:权重分配应该反映各因子在特定行业中的信息可靠性。
估值区间与投资信号
综合得分有了,最后一步是把连续的 0-100 分划分为离散的估值区间:
def get_valuation_zone(score):
if score < 20: return "deeply_undervalued" # 极度低估
if score < 40: return "undervalued" # 低估
if score > 80: return "deeply_overvalued" # 极度高估
if score > 60: return "overvalued" # 高估
return "normal" # 正常
这个阈值划分并不是随意的。20/40/60/80 的切分对应正态分布的大致分位点,使得在"随机漫步"假设下,一个指数大约 20% 的时间处于低估/高估区间。
但需要注意的是,估值模型给出的是胜率提升而非确定性结论。综合得分 15 不意味着"现在买一定赚钱",而是意味着"从历史统计来看,在这个估值水平买入,持有 3-5 年获得超额收益的概率显著高于均值"。
从宽基到行业:同一框架的不同参数
一个有趣的发现是:无论是对沪深 300、中证 500 这样的宽基指数做估值,还是对钢铁、医药、消费这样的行业指数做估值,最终选出的因子都收敛到了同一个答案——PE 百分位 + PB 百分位 + ERP。
这不是巧合,而是因子正交性分析的自然推论。既然这三个因子已经覆盖了估值判断所需的全部独立信息维度,那么不管被评估的对象是宽基指数还是行业指数,最优因子选择都应该是一样的。
区别仅在于参数配置:
- 权重不同:宽基指数用相对均衡的权重,行业指数按类别差异化配置(如前文所述,周期行业偏重 PB,消费行业偏重 PE)
- 特殊处理:行业需要处理 Molodovsky 效应(PE/PB 取反),宽基指数通常不需要
- 阈值不同:不同行业的估值区间阈值可以独立配置(有些行业 30 分就算低估,有些要 25 分)
核心的评分引擎——因子评分、线性插值、动态阈值调整、加权合成——完全通用。这种"同一框架、不同参数"的统一性,让模型的维护和扩展变得非常简洁。
行业里大家都是怎么做估值的
在我们自己设计模型之前,有必要看看市面上的主流估值平台都在用什么方法。这既是知己知彼,也是为了理解我们的模型在整个光谱上处于什么位置。
单因子百分位流派:蛋卷(雪球)基金、理杏仁
这是目前使用最广泛的估值方法,蛋卷(雪球)基金的"指数估值"和理杏仁的估值数据都属于这一类。核心思路非常直接:取一个指数的 PE(或 PB),计算其在过去 N 年的历史百分位,然后简单地划线——百分位低于 30% 算低估,高于 70% 算高估,中间算适中。
蛋卷(雪球)的"估值表"可能是很多基金定投者接触到的第一个估值工具。它的优势是极度简洁:一个数字告诉你贵不贵,一目了然。但这种简洁是有代价的:
第一个问题是"PE 还是 PB"的选择困境。 不同平台在不同指数上会选用不同的指标。比如银行指数通常看 PB 百分位(因为银行的盈利受坏账拨备影响波动大),消费指数看 PE 百分位。但这个选择本身就是一次人为判断——为什么不能两个都参考?单因子方法强制你在 PE 和 PB 之间二选一,丢弃了另一个维度的信息。
第二个问题是百分位的时间窗口差异。 理杏仁提供了"近5年"、"近10年"、"全历史"等多种百分位口径。同一个指数在不同口径下,百分位可能差异巨大——比如一个指数近 5 年 PE 百分位 70%(看起来偏贵),但近 10 年百分位只有 40%(其实正常)。这是因为过去 5 年的估值中枢本身就比 10 年均值低。选哪个口径?没有标准答案,用户自己做判断。
第三个问题,也是最根本的问题:完全忽视利率环境。 2020 年和 2024 年,沪深 300 的 PE 可能都是 12 倍,PE 百分位可能相近。但 2020 年 10 年期国债收益率在 3.0% 以上,2024 年已经降到了 2.0% 以下。利率大幅下行意味着"12 倍 PE"在 2024 年的含金量远高于 2020 年——盈利收益率相对无风险利率的超额收益更大了。纯粹的 PE 百分位对此视而不见。
估值温度流派:有知有行
有知有行的"温度计"是国内个人投资者中影响力最大的估值工具之一。它把估值抽象为一个 0°-100° 的"温度",直觉上非常友好——温度越低越"冷"(便宜),越高越"热"(贵)。
相比蛋卷的单因子,有知有行做了一些改进。它的全市场温度基于万得全 A 等权 PE 的历史百分位计算,而指数层面引入了"内在收益率"(本质上就是盈利收益率 1/PE)作为辅助参考。同时,它的宏观数据板块展示了 10 年期国债收益率、GDP 增速等信息,暗示用户应该在更大的框架下理解估值温度。
但温度计的核心计算逻辑仍然是单维度的百分位排名。它没有在模型层面将利率环境纳入评分——国债收益率只是作为旁边的"参考数据"展示,不参与温度的计算。至于 PB、股息率这些指标,也只是作为指数层面的附加展示,不影响最终的温度读数。
换言之,温度计的 UX 比蛋卷好很多(视觉化、有宏观数据辅助),但底层模型的信息维度其实差不多。
FED 模型流派:学术界与部分机构
在学术和机构领域,有一个经典的估值框架叫做 FED 模型(得名于美联储,虽然美联储官方从未正式背书过这个模型)。它的核心思想非常简洁:
如果 盈利收益率 (1/PE) > 国债收益率 → 股票便宜
如果 盈利收益率 (1/PE) < 国债收益率 → 股票贵
这其实就是 ERP 的前身。FED 模型把股市估值直接与债券收益率挂钩,解决了纯百分位方法忽视利率的问题。但它也有明显的缺陷:
- 没有百分位的概念。 它只看绝对值,不关心当前 ERP 在历史中的位置。一个 ERP = 3% 是高是低?在利率环境稳定的时候很好判断,但在利率大幅波动的时期就需要更多上下文。
- 单一维度。 FED 模型只看盈利收益率 vs 债券收益率,不看 PB、不区分行业特征。它本质上是一个"股债性价比"指标,不是一个完整的估值模型。
- 固定阈值问题。 传统 FED 模型用"ERP = 0"作为分界线,但这条线在不同市场(A 股 vs 美股)和不同时期(高利率 vs 低利率)的有效性差异很大。
我们的三因子模型在做什么不同的事
把上面三种流派放在一起对比,就能清楚看到我们的三因子模型在整个光谱上的位置:
| 维度 | 蛋卷/理杏仁 | 有知有行 | FED 模型 | 三因子模型 |
|---|---|---|---|---|
| 盈利估值 (PE) | PE 百分位 | PE 百分位(温度) | 1/PE 绝对值 | PE 百分位 |
| 资产估值 (PB) | 二选一 | 展示但不参与计算 | 不涉及 | PB 百分位 |
| 利率环境 | 不涉及 | 展示但不参与计算 | 核心(但无百分位) | ERP 动态评分 |
| 多因子加权 | 否 | 否 | 否 | 按行业类别差异化 |
| 周期行业处理 | 人工选 PB | 无特殊处理 | 无 | Molodovsky 取反 |
| 数据缺失策略 | 显示可用数据 | 显示可用数据 | 不适用 | 严格拒绝输出 |
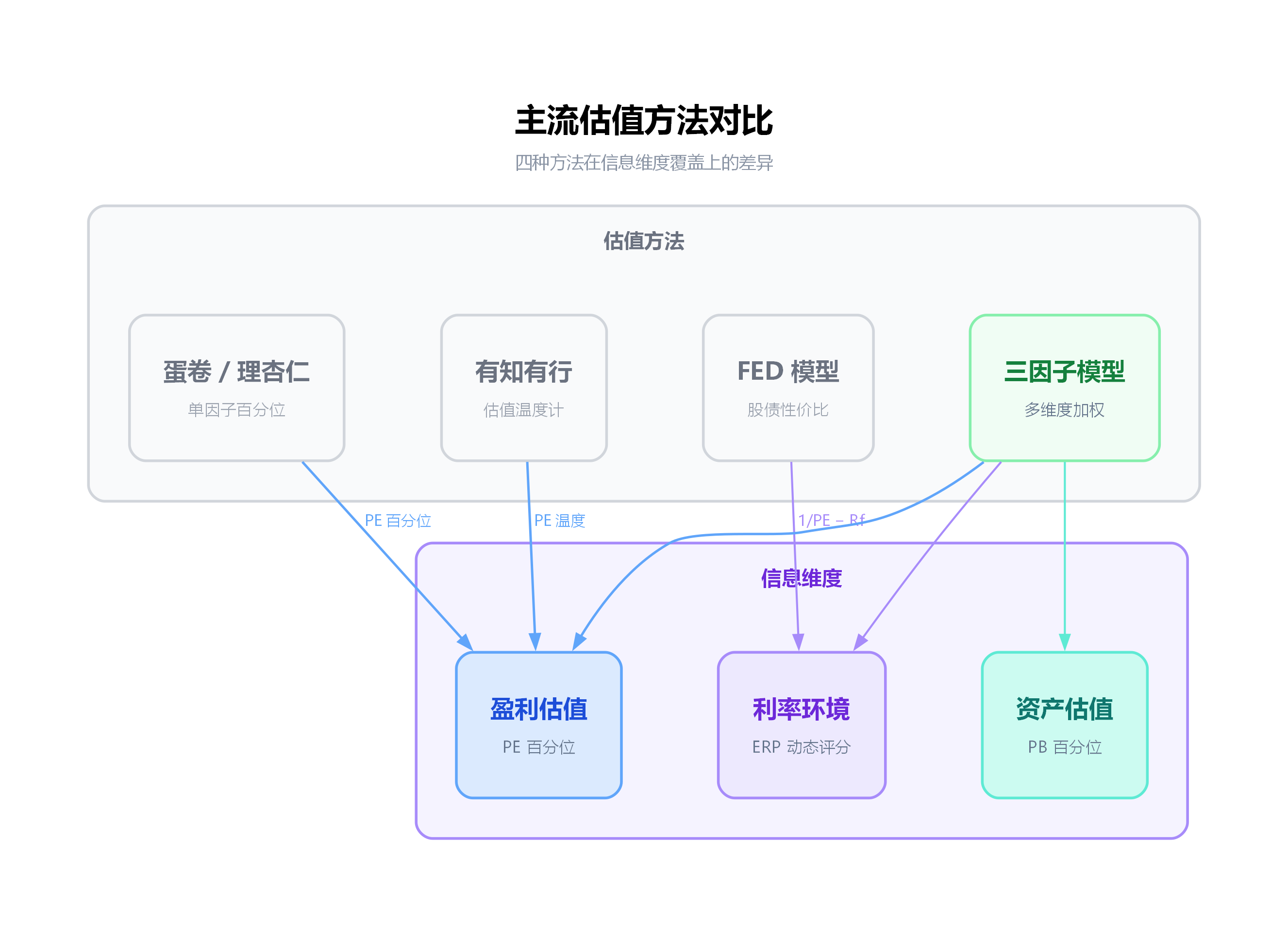
简单来说,三因子模型做的是把三个流派各自做对的部分组合在一起:
- 从百分位流派借鉴了"与自身历史比较"的思想(PE 百分位 + PB 百分位)
- 从 FED 模型借鉴了"考虑利率环境"的思想(ERP)
- 在此基础上增加了百分位方法和 FED 模型都没做的事:多因子加权、按行业差异化配置权重、动态阈值调整
当然,这种组合不是免费的午餐——模型变得更复杂了,可解释性也降低了。一个用户看到"综合得分 35"时,他未必能快速理解这个数字背后是 PE 百分位、PB 百分位和 ERP 三个维度按特定权重加权的结果。因此在实际应用中,建议同时展示完整的评分分解(每个因子的原始值、百分位、得分、权重贡献),让使用者在需要时可以"拆开黑盒"看里面。
模型的局限性
最后,必须诚实地讨论这个模型做不到什么。
第一,它不包含任何基本面质量因子。 ROE、营收增速、自由现金流这些衡量企业"好不好"的指标,完全不在模型的考量范围内。模型只回答"贵不贵",不回答"值不值"。一个 ROE 持续恶化的行业,即使 PE 百分位降到 10%,也可能是"便宜有便宜的道理"。这是设计上的有意取舍——估值模型的职责是判断价格水位,而非企业质量,两者应该由不同的模块各司其职。
第二,百分位参考的是"过去"。 如果一个行业正在经历结构性变化(比如互联网行业从高增长转向成熟期),那么过去十年的估值分布可能不再适用于未来。模型会告诉你"当前 PE 处于历史 20% 分位",但它不会告诉你这个行业的估值中枢是否已经永久性下移。
第三,ERP 的动态调整系数是经验值。 adjustment_rate = 0.5 这个参数没有严格的理论推导,它是一个在回测中表现尚可的折中值。在极端利率环境下(比如零利率或负利率),这个线性调整假设可能不够准确。
第四,模型是事后校验的,不是预测工具。 综合得分低不代表明天就要涨,它只代表"如果历史模式重演,这个位置的安全边际比较厚"。而历史不一定会重演。
结语
回顾整个推导过程,这个三因子模型的核心思路可以用一句话概括:用最少的、正交的因子,覆盖估值判断所需的全部信息维度。
PE 百分位回答"盈利定价在历史中的位置",PB 百分位回答"资产定价在历史中的位置",ERP 回答"相对于无风险利率,股票还有没有吸引力"。三个问题,三个因子,没有冗余,没有遗漏。
而从五因子到三因子的精简过程,本身也是一个值得反思的教训:在模型设计中,增加复杂度是容易的,识别冗余是困难的。 五个因子看起来更"全面",但如果其中三个都在说同一件事,那模型实际上并没有因此变得更聪明——它只是在用更复杂的方式重复自己。
这大概也是投资和工程的共通之处:真正有价值的不是堆砌更多的指标,而是理解每一个指标到底在告诉你什么,以及它和其他指标之间到底是互补关系还是同义反复。