AI 真能自己写出整个 Windows 系统吗?我做了一场无监督实验
提示
Cursor 团队用上百个 Agent 跑了几周,产出了 120 万行的 Windows 7 模拟器和 100 万行的浏览器。OpenAI 内部用 Agent Loop 五个月写了 100 万行代码。我决定自己验证一下——造了一个框架,给个种子文件,让 AI 无限跑下去。结果发现,真正的难点根本不在模型能力。
他们真的在用 AI 写 Windows
2026 年初,Cursor 团队发表了一篇 Scaling Agents 的文章,其中的实验数据相当震撼:
- 浏览器:约 1,000 个文件,超过 100 万行代码,跑了将近一周
- Windows 7 模拟器:14,600 次 commits,120 万行代码
- Excel 公式引擎:12,000 次 commits,160 万行代码
"上百个 Agent 可以在同一个代码库上协同工作数周"——这是他们的原话。整个实验消耗了数万亿个 token。
与此同时,OpenAI 也在自家的 harness engineering 文章中透露:一个 3 到 7 人的小团队,用 Codex Agent Loop 跑了 5 个月,合并了约 1,500 个 PR,产出了 100 万行代码——零手写代码。
社区也没闲着。OctopusGarden 自称"开源软件暗工厂",用无限循环生成代码直到满意度达到 95%;WorkOvernight 让 Claude Code 在你睡觉时自动写代码;YC W26 的 Emdash 在做并行 Agent 编排。
这些实验看起来相当成功。但如果仔细读 Cursor 那篇文章,你会发现他们也坦承了不少问题:Agent 的注意力会随时间漂移,flat peer-to-peer 协调会导致吞吐量坍缩——20 个 Agent 的实际产出可能只相当于 2-3 个。Agent 在没有层级管理的情况下,倾向于做小而安全的改动,回避真正的难题。
我想亲自验证一下:在完全无人监督的情况下,给 AI 无限的时间,它到底能把一个项目推进到什么程度?
两种死法
为了回答这个问题,我造了 AutoForge 的第一个版本——一个极简的无限循环框架。
设计很简单:写一个种子文件(seed.md),描述你想要的项目目标,然后让 AI Agent 无限循环、无人监督、无时间限制地自主开发。每一轮,Agent 分析项目现状,生成任务,执行任务,再进入下一轮。理论上,只要模型够强,时间够长,它应该能不断推进项目。
实际跑起来之后,我发现了两种截然不同的失败模式。
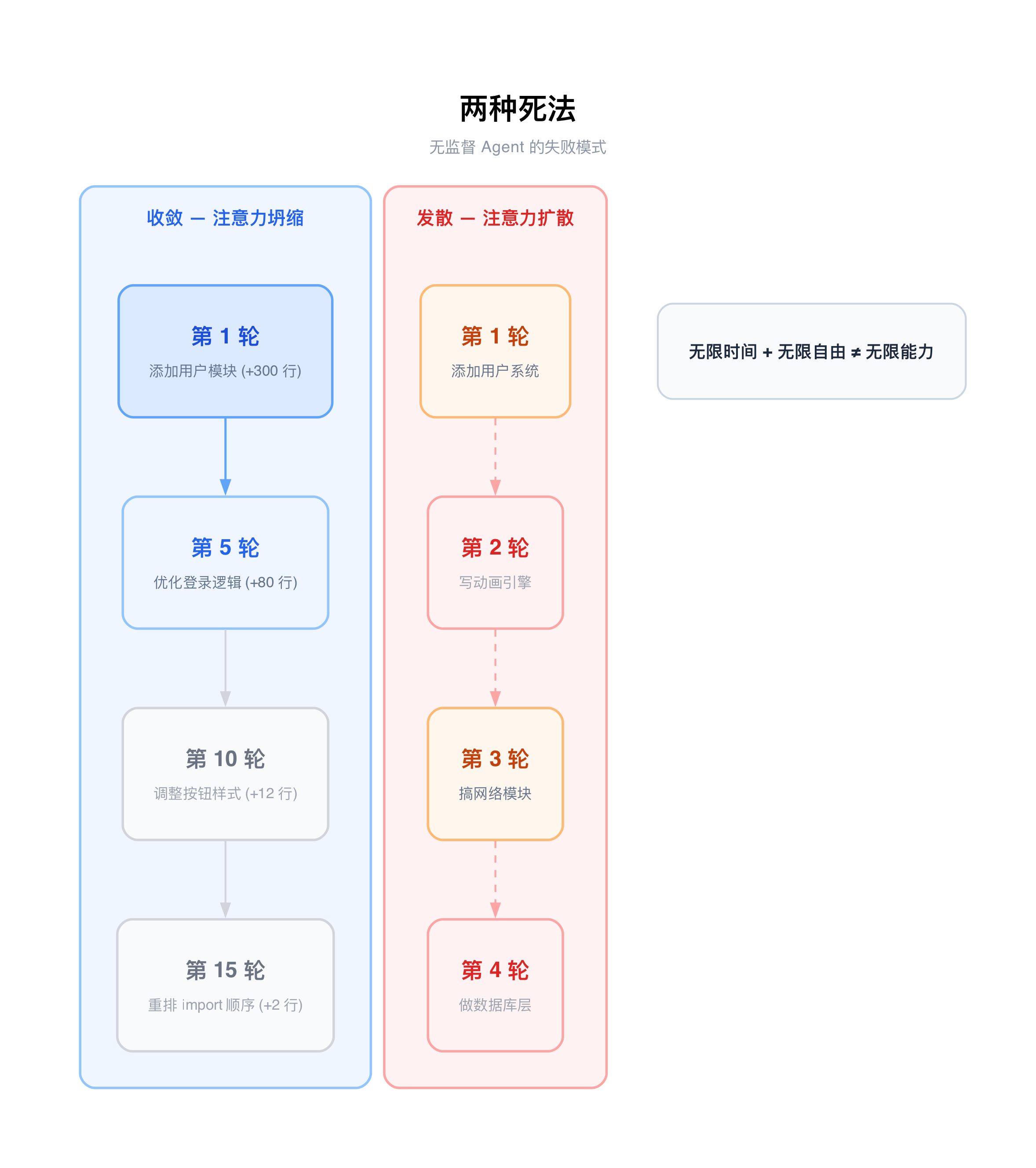
收敛——注意力坍缩
第一种死法是收敛。Agent 在跑了若干轮之后,任务列表开始萎缩。diff 从几百行缩到几十行,再缩到几行。Agent 开始反复调整同一个模块的细节——改改按钮样式、优化一下日志格式、重新排列一下 import 顺序。
从 Agent 的视角来看,它觉得项目"已经很好了",找不到什么新的事情可做。但从人类的视角看,项目可能还有大量功能没有实现,只是 Agent 的注意力坍缩到了一个局部最优点,无法跳出来。
这和 Cursor 团队描述的现象高度吻合:他们也发现 Agent 在长时间运行后会发生 drift,需要定期重启来避免。
发散——注意力扩散
第二种死法恰好相反,是发散。Agent 每一轮都往不同的方向撒点——这轮加个用户系统,下轮搞个动画引擎,再下轮又去写网络模块。没有方向,没有聚焦,到处开花但哪朵都不结果。
代码库快速膨胀,模块之间缺乏协调,质量完全不可控。本质上,没有约束的创造力等于噪声。自由度太高,反而什么都做不好。
一个残酷的结论
无论是收敛还是发散,结论都指向同一个事实:无限时间 + 无限自由 ≠ 无限能力。
裸模型不会因为跑得更久就变得更强。给它再多的时间,它也不会自发地产生"退后一步看全局"的能力,也不会自动平衡注意力的分配。Cursor 团队在实验中也得出了类似的结论——他们从 flat peer-to-peer 协调演进到了 Planner-Worker 分层架构,本质上就是在给 Agent 加约束。
那么问题来了:约束应该怎么加?
问题出在环境,不在模型
带着这个问题去查资料,我找到了 OpenAI 2026 年 2 月发的那篇 harness engineering 文章。读完之后的感受很直接:原来人家那 100 万行代码不是模型裸跑出来的。
他们的核心发现是:
"The bottleneck was never the agent's ability to write code, but rather the lack of structure, tools, and feedback mechanisms."
换句话说,瓶颈不在模型的代码能力,而在于缺少结构、工具和反馈机制。他们把模型之外的所有这些东西统称为 harness——Agent 的"缰绳"。
Agent = Model + Harness。模型是马,harness 是缰绳。没有缰绳的马只会乱跑。
Martin Fowler 随后在 Harness Engineering for Coding Agent Users 中给出了更系统化的框架。他借用了控制论的概念,把 harness 分为两类控制:
- Guides(前馈控制):在 Agent 行动之前引导它。比如 CLAUDE.md 配置文件、架构文档、角色定义。
- Sensors(反馈控制):在 Agent 行动之后检测和纠正。比如 linter、测试套件、代码审查。
每种控制又可以是计算性的(确定性的,比如跑测试)或推理性的(非确定性的,比如让另一个 LLM 审查代码)。
简单来说,Prompt Engineering 管的是"问什么",Context Engineering 管的是"给 LLM 看什么上下文",而 Harness Engineering 管的是"整个运行环境怎么设计"——它是最上层的学科,前两者是它的子集。

回过头看我的实验,AutoForge v0 的失败原因就很清楚了:不是模型不行,是 harness 压根不存在。我给了 Agent 一匹好马,但忘了给它缰绳。
给野马套缰绳:AutoForge 的进化
想明白这一点之后,我开始系统性地给 AutoForge 加上各种 harness 机制。每一个机制的加入,都是被实际遇到的问题逼出来的。
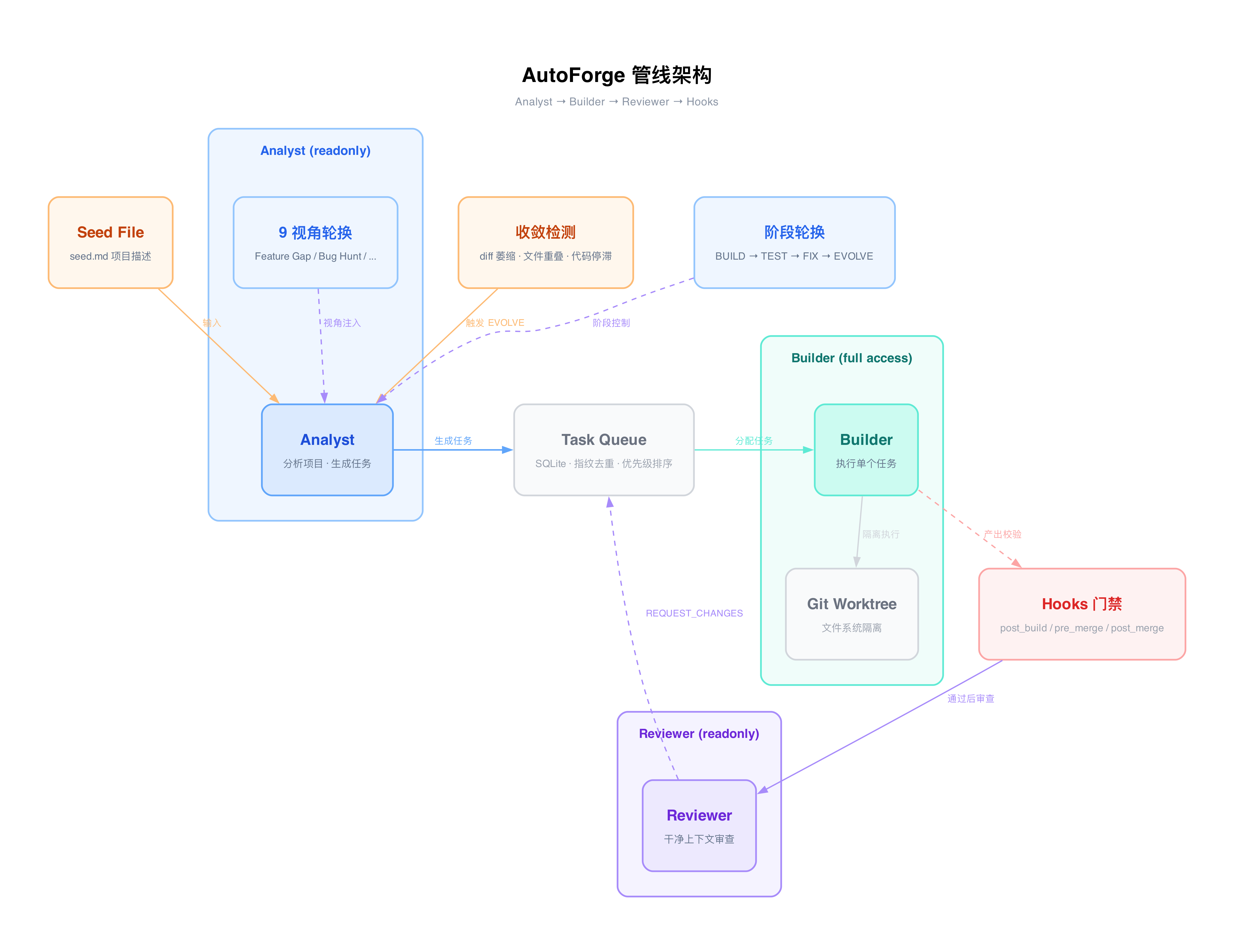
三角色流水线
AutoForge v0 最大的问题之一是角色混乱——一个 Agent 既要分析项目、又要写代码、还要评估质量。这就好比让同一个人出题、答题、阅卷,结果可想而知。
于是我把职责拆成了三个独立角色:
- Analyst:分析项目现状,从特定视角出发,生成 5-10 个任务写入任务队列。它只有 readonly 权限,看得见代码但碰不了。
- Builder:从队列中领取一个任务,专注执行。拥有完整的文件读写权限。
- Reviewer:独立审查 Builder 的产出,给出 APPROVE / REQUEST_CHANGES / REJECT 三种判决。同样是 readonly。
这种权限隔离不是靠 prompt 来约束的——Analyst 配置了 --allowedTools Read,Glob,Grep,在 CLI 层面就被限制了写入能力。如果规则重要,就别交给 AI 来遵守。
每个角色还可以使用不同的模型。分析任务用 Sonnet 省钱,构建任务用 Opus 保质量,审查任务用另一个模型增加视角多样性——这样还能降低关联性错误的概率。
确定性门禁
三角色分离解决了职责混乱的问题,但还有一个更隐蔽的陷阱:Agent 会撒谎。
不是说它故意骗你,而是 LLM 有时候会在输出中声称"我已经运行了测试,全部通过"——但实际上它可能根本没跑。这在有人监督时还好发现,在无监督场景下就是灾难。
OpenAI 在 harness engineering 中提出了一个原则:"if a rule matters, enforce it mechanically"——如果规则重要,就用机械方式强制执行。
AutoForge 的 Hooks 系统就是这个原则的落地。它在流水线的三个阶段插入 shell 命令:
- post_build:Builder 完成后,自动运行构建验证和测试
- pre_merge:并行模式下,合并到主分支前的检查
- post_merge:合并后的集成验证
这些 hook 是 shell 命令,不是 prompt 指令。它们是确定性的——跑就是跑了,没跑就是没跑。即使 hook 返回了 exit code 0,系统仍然会扫描 stdout 中的 error、FAILED、BUILD FAILED 等模式作为双重保险。required: true 的 hook 失败直接阻断流水线,required: false 的只记录警告。
用 Fowler 的框架来说,这是一个计算性的反馈 sensor——确定性的、不依赖模型的质量门禁。
干净上下文审查
Writer-Reviewer 模式本身不新鲜,但 AutoForge 的实现有一个关键细节:Reviewer 在完全干净的上下文中运行,看不到 Builder 的任何对话历史。
这解决的是认知污染问题。如果 Reviewer 能看到 Builder 的推理过程——"我之所以这样写是因为……"——它很容易被带偏,变成橡皮图章。干净上下文意味着 Reviewer 只看到任务描述和 git diff,必须独立判断代码质量。
Reviewer 给出 REQUEST_CHANGES 时,反馈会被存储为任务的失败原因。下次重试时,Builder 能在 prompt 中看到这些反馈,从而有针对性地改进。这形成了一个跨 Agent 的反馈回路。
还有一个务实的安全设计:如果 Reviewer 自身超时或输出解析失败,默认判定为 APPROVE。审查基础设施的故障不应该阻断生产流水线。
反收敛:解决最难的问题
前面的机制解决了"做对"的问题,但在无监督场景下,还有一个更根本的挑战:如何让 Agent 持续做新的事?
这是 harness engineering 文献中尚未被充分讨论的方向。OpenAI 和 Fowler 的框架都聚焦于质量保证,但对于一个要无限运行下去的系统来说,反收敛才是生死攸关的问题。
AutoForge 为此设计了四层防御体系:
第一层:9 视角轮换。 Analyst 每次运行时,会被分配一个特定的分析视角:Feature Gap(功能缺口)、Bug Hunt(缺陷排查)、Test Coverage(测试覆盖)、Performance(性能审计)、Code Quality(代码质量)、Content(内容完整性)、UX(用户体验)、Integration(系统集成)、Resource Pipeline(资源管线)。每轮自动切换到下一个视角。
这是一个前馈引导——在 Agent 分析之前就限定了它的观察角度,强制它从不同维度审视项目。
第二层:任务指纹去重。 对每个任务的标题和描述做 SHA256 哈希,截取前 16 位作为指纹,在数据库层通过 UNIQUE 约束去重。语义相同的任务无论被多少轮 Analyst 生成,都只会被执行一次。
这是一个计算性的反馈 sensor——确定性的、零误判的。
第三层:区域注意力均衡。 数据库中维护了一张 area_attention 表,记录每个代码区域被触碰的次数和最后触碰时间。任务分配时优先选择最少触碰的区域。这样做的效果是实现了一种类似 round-robin 的覆盖策略,防止 Agent 沉迷于某一个子系统。
第四层:收敛检测 + 逃逸。 系统持续监控三个指标:
- diff 萎缩:如果最近几轮的 git diff 行数都低于阈值,且呈下降趋势
- 文件重叠:如果最近几轮修改的文件高度重叠(重叠率 > 80%)
- 代码停滞:如果总代码行数的波动范围低于阈值
任何一个指标触发,系统就会强制切换分析视角,并进入 EVOLVE 阶段——让 Analyst 完全重新规划,打破当前的注意力困局。
这里有一个巧妙的防死锁设计:EVOLVE 阶段之后,系统会跳过收敛检测。原因是 Analyst 只分析不写代码,它产生的 git diff 必然为零——如果不跳过,收敛检测会立刻再次触发,形成无限 EVOLVE 循环。
用 Fowler 的 2×2 矩阵来对照,这四层恰好覆盖了控制论的全部象限:
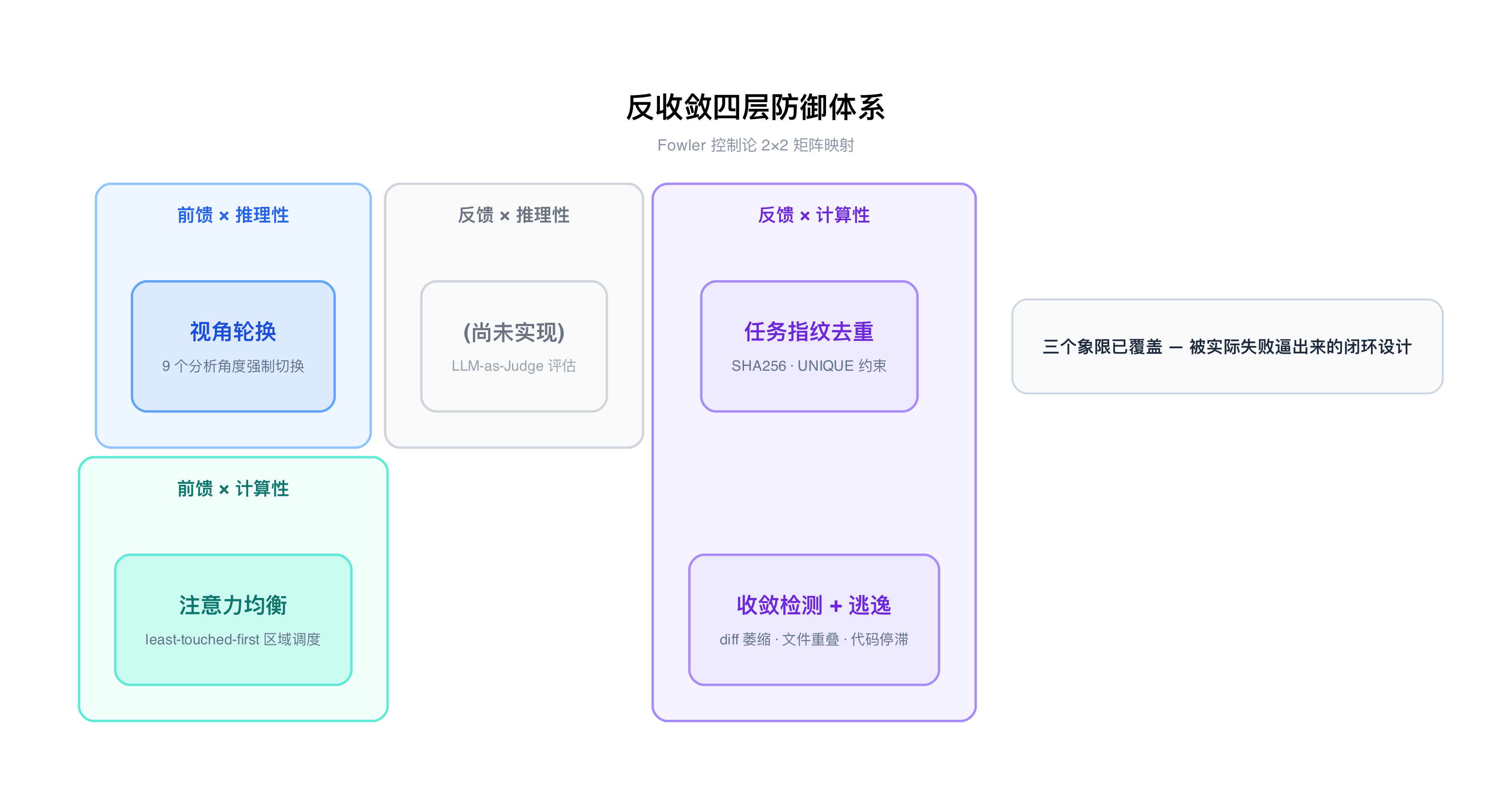
- 视角轮换:前馈 × 推理性
- 指纹去重:反馈 × 计算性
- 注意力均衡:前馈 × 计算性
- 收敛检测:反馈 × 计算性
不是刻意设计的——是被失败逼出来的。
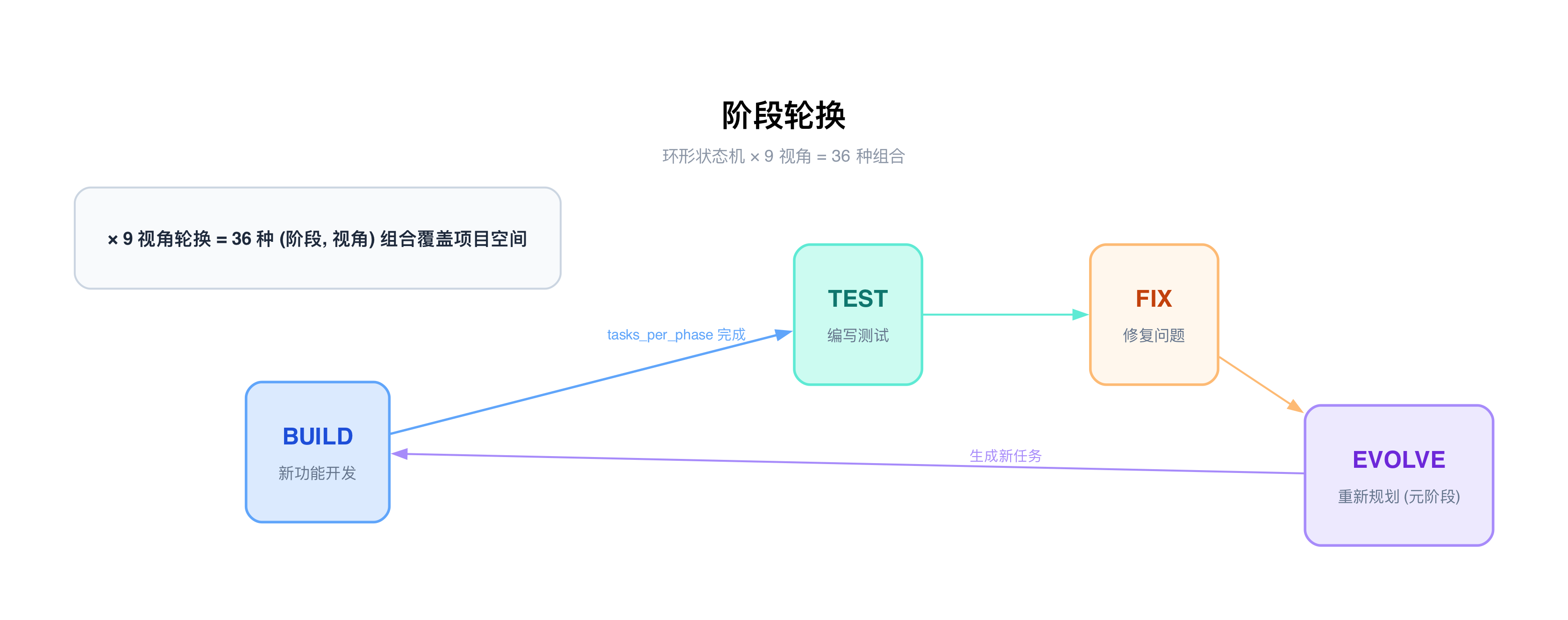
阶段轮换
AutoForge 的执行流程不是线性的,而是一个环形状态机:BUILD → TEST → FIX → EVOLVE → BUILD → ...
每个阶段完成一定数量的任务(tasks_per_phase)后自动切换到下一个。EVOLVE 是一个特殊的元阶段——它不执行代码,只让 Analyst 退后一步重新规划任务。当任务队列耗尽时,系统也会自动进入 EVOLVE 行为,不会因为没活干就停滞。
4 个阶段 × 9 个视角 = 36 种组合。这意味着系统在每 36 轮循环中会从完全不同的角度和阶段组合来审视项目,大幅减少了盲区。
并行构建
当单个 Builder 的吞吐量不够时,AutoForge 支持多 Builder 并行。这里用的是 Git Worktree 方案——每个 Builder 在独立的 worktree 中工作,真正的文件系统隔离。
并行带来的最大风险是合并冲突。AutoForge 用了三层防御:
- 区域级并发控制:同一个 area 同一时间只允许一个 Builder 工作。从源头减少冲突的可能。
- 全局 merge lock:所有合并操作串行执行。先尝试 rebase 保持线性历史,rebase 失败则回退到 merge。
- 自动冲突解决:对常见的"双方都在添加新内容"类型的冲突,用正则匹配冲突标记并保留双方内容。解决不了的才放弃。
另外还有一个实用的优化:后台预取。当任务队列快要见底时,Builder 还在工作的同时,Analyst 已经在后台线程中生成下一批任务了。这样流水线不会因为等待分析而停滞。
Cursor 团队在 Scaling Agents 中也得出了类似的架构演进结论——他们从 flat peer-to-peer 演进到了 Planner-Worker 分层架构,和 AutoForge 的 Analyst-Builder 分离不谋而合。
做得到什么,做不到什么
AutoForge 加上这些 harness 机制之后,效果和 v0 有了质的区别。在给定一个清晰的种子文件的情况下,它可以持续数百轮不收敛、不发散地推进项目,每一轮都产生有意义的代码增量。
但它也有明确的局限:
- 它不能替代人类的架构判断。seed 文件的质量决定了天花板。一个模糊的种子文件只会产出模糊的代码。
- 它不能自主发现需求。它能很好地把需求拆解成任务并执行,但"用户到底想要什么"这件事,仍然需要人来定义。
- 它在处理跨模块的深层依赖时仍然会出错,尤其是当修改需要同时协调多个子系统的设计时。
那么回到最初的问题:AI 真能自己写出整个 Windows 系统吗?
Cursor 的实验证明了规模上是可行的——120 万行的 Windows 7 模拟器确实被生产出来了。但他们的文章同时也揭示了大量的工程挑战:drift、注意力坍缩、Agent 回避难任务、协调机制的瓶颈。
我的结论是三条:
- 模型能力是必要条件——没有足够强的模型,什么 harness 都救不了。
- Harness 是充分条件——同样的模型,有没有 harness,产出天差地别。
- 需求清晰度是前提条件——AI 能忠实地执行你描述的东西,但它不会替你想清楚你想要什么。
那些演示视频里看起来 AI 在"自主"开发,实际上背后都有大量的 harness 工程在支撑。省略了这些,就制造了"模型裸跑"的假象。
如果你对无监督自主开发这个方向感兴趣,AutoForge 是完全开源的,它实现了上述所有的 harness 机制,可以直接拿来跑实验。
结语
Harness 不是在限制 AI,恰恰相反,它是让 AI 的能力能够可持续地释放出来的基础设施。没有缰绳的马跑得很快,但跑不远,也跑不准。
模型在快速迭代,各家的能力在趋同。但 harness 的设计——怎么拆分角色、怎么设计反馈回路、怎么对抗收敛、怎么保证质量——这些才是真正需要工程经验积累的部分。
OpenAI 给出了 harness engineering 的理论框架,Cursor 提供了规模化实验的数据,而 AutoForge 则是我个人把这些理论落地为可运行框架的一次实践。
这个方向还有很多未解的问题:行为正确性的自动验证仍然是最大的难题;harness 本身的复杂度如何控制;随着模型能力增强,哪些 harness 可以逐步拆掉。但至少有一件事是确定的:未来的 AI 工程师,与其说是在写代码,不如说是在设计缰绳。