Coding Agent 的进化之路 —— 从代码建议到自主编程
提示
2025 年,软件开发正在经历一场范式转变。Coding Agent 从最初的代码补全建议者,进化到了能够自主规划、执行、验证的闭环编程系统。但在这条进化之路上,上下文丢失、成本膨胀、远程协作等工程问题接踵而至。本文将以全景视角,串讲 Coding Agent 在架构设计上的关键改进与优化模式,探讨它离真正"自主编程"还有多远。
从建议者到指挥者
如果你在 2023 年使用过 GitHub Copilot,那你一定对"Tab 补全"这个交互模式不陌生——AI 在你写代码的时候提供一行或几行建议,你按 Tab 接受,或者忽略继续往下写。这种模式是经典的 代码建议者(Code Suggester) 范式,AI 的角色仅仅是一个被动的补全工具。
回顾这段历史,代码补全工具的进化经历了几个明确的阶段:
- 静态补全时代(~2020 年前):基于语法树和符号表的传统 IDE 补全,只能提示已存在的变量名和方法签名
- 语言模型补全时代(2021-2023):以 Copilot 为代表,基于 Codex/GPT 模型预测下一行代码,但仍然是被动的"建议者"角色
- 对话式编程时代(2023-2024):ChatGPT、Copilot Chat 等产品引入对话交互,开发者可以用自然语言描述需求,AI 生成代码片段——但生成的代码仍需开发者手动复制、粘贴、调试
- 自主编程时代(2025-至今):Coding Agent 直接操作文件系统、运行终端命令、执行测试,形成真正的闭环
但到了 2025 年初,事情发生了根本性的变化。
以 Claude Code CLI 为代表的新一代 Coding Agent,不再只是"建议"你该写什么代码,而是接管了整个开发流程:理解需求、制定计划、编写代码、运行测试、修复 bug、提交 PR。开发者的角色从"代码的编写者"变成了"任务的指挥者" —— 用自然语言描述你想要什么,然后审查 Agent 交付的结果。
这种范式被称为 计划-执行闭环(Plan-Execute Loop)。终端(Terminal)作为整个架构的"重心",这么做的核心目的是为了透明度与可审计性:Agent 的每一步行为都显式可见,开发者可以像指挥家一样实时"指挥"和纠偏整个编码过程。
一个典型的 Plan-Execute Loop 大致如下:
用户输入需求 → Agent 分析并生成执行计划 → 逐步执行(编辑文件/运行命令/调用 API)
↑ ↓
←———————————— 反馈观察结果(测试输出/报错信息/LSP 诊断) ←——————————
在这个循环中,Agent 不仅要"写"代码,还要"理解"代码执行的结果。当测试失败时,它能读取错误栈、定位问题根因、修改代码、重新运行测试——整个过程可以完全自动化,无需人类干预。这和传统的"代码生成"有本质区别:传统工具只负责"生成",而 Agent 还负责"验证"和"修正"。
但这种转变也带来了一种新的心理压力。开发者不再因为编写数千行代码而感到体力疲惫,取而代之的是每小时需要进行数十次微观决策——审查代码差异、批准文件更改、验证架构选择——而产生的 决策疲劳。
想象一下这个场景:Agent 连续修改了 15 个文件来实现一个新功能,你需要逐一审查每个文件的变更,判断它的设计决策是否合理、命名是否恰当、边界条件是否考虑到了。这种认知负担完全不亚于自己写代码,只是从"实现疲劳"转向了"决策疲劳"。
更微妙的是,这种疲劳带来了一个危险的倾向——审查懈怠(Review Fatigue)。当 Agent 连续交付 20 个看起来"差不多对"的变更时,开发者很容易开始无脑点击"Approve"。而一旦养成这种习惯,Agent 引入的微妙 bug 或设计缺陷就可能悄无声息地溜进代码库。这恰恰是这场范式革命中尚未完全解决的人机交互命题——如何在保持效率的同时,让开发者始终保持足够的警觉性?
"记忆"问题:长周期任务中的上下文管理
Coding Agent 在处理一个简单的 bug 修复时表现优异,但当任务复杂度上升——比如一个跨越多个文件、需要持续数小时甚至数天的大型重构——问题就来了:AI 会"忘记"之前做过什么。
这不是 AI 变傻了,而是 LLM 的上下文窗口天然有限。即使是 2026 年初最先进的模型,标准上下文窗口也不过 200K Token。当对话历史累积到一定长度后,早期的关键信息就会被挤出窗口之外。你告诉它的架构决策、你们讨论过的设计权衡、之前修改过哪些文件——这些关键信息可能在几十轮对话后就消失了。这个问题在业界被称为"上下文丢失"或"记忆失效",它直接制约着 Coding Agent 处理大型工程任务的能力。
这个问题有多严重?举一个真实的例子:在一个需要重构身份认证模块的任务中,Agent 在第 1 轮对话中理解了"我们要从 session-based 迁移到 JWT"这一核心决策,但到了第 30 轮对话时,它突然生成了一段基于 session 的代码——因为那个关键决策早已被挤出了上下文窗口。更糟糕的是,开发者如果没有仔细审查,这种"回退"可能直接被合入代码库。
那么,如何解决这个问题?下面以 OpenCode 为例,介绍三层解决方案。其他 Coding Agent 也有相似的机制来保证长周期任务的可靠性。
第一层:实时环境感知(LSP 集成)
当 AI 使用 edit 工具修改代码后,OpenCode 的全局事件总线会立即向 LSP(Language Server Protocol)服务器发送通知。服务器返回的实时诊断信息(语法错误、类型不匹配、未定义变量等)会作为"观察结果"直接反馈给 LLM。
简单来说,AI 改完代码后不需要靠"记忆"来判断改得对不对,编辑器会实时告诉它哪里有问题。这就像一个永远不会走神的 Code Review 搭档,每一次代码变更后都会立即检查并反馈。
传统 IDE 中,LSP 主要服务于人类开发者——提供代码补全、错误高亮、跳转定义等功能。但在 Coding Agent 的场景下,LSP 被赋予了一个全新的角色:它是 Agent 的"感官系统"。Agent 通过 LSP 获得的不仅仅是"当前文件有没有语法错误"这种局部信息,而是整个项目的全局健康状态。
举个栗子:AI 在文件 A 中重命名了一个函数,但忘记更新文件 B 中对该函数的调用。在传统模式下,这个错误可能要等到最后运行测试才会暴露。而有了 LSP 集成后,AI 修改文件 A 的瞬间就会收到文件 B 的诊断信息——"未定义的函数引用"——然后立即去修复。
此外,LSP 还能自动进行文件间的函数引用和定义跳转,显著减少了 Agent 为了查找代码而消耗的 Token。这一点非常关键:在一个大型项目中,Agent 如果要靠 grep 逐文件搜索来理解代码结构,可能光搜索就要消耗掉上下文窗口的一大半。而 LSP 的"跳转到定义"只需要一次调用就能精确定位。
具体来说,LSP 为 Agent 提供的关键能力包括:
- goToDefinition:精确跳转到符号定义处,避免 Agent 盲目搜索
- findReferences:找到某个函数/变量的所有引用点,确保重命名或重构时不遗漏
- hover:获取类型信息和文档注释,帮助 Agent 理解代码语义
- diagnostics:实时诊断,相当于给 Agent 配了一个永不下线的 TypeScript 编译器
这些能力组合在一起,让 Agent 从"靠记忆编程"进化到了"靠感知编程"——即使它忘记了之前的对话内容,LSP 也能实时告诉它当前代码的状态。
第二层:持久化会话存储(SQLite)
第一层解决的是"实时感知",而这一层解决的是更根本的问题——断点续传。
LLM 本质上是无状态的——每次 API 调用都是独立的,模型不会"记住"上一次调用的内容。所有的"记忆"都依赖于将历史对话作为 prompt 重新发送。这意味着,如果没有持久化机制,关闭终端就等于失忆。
OpenCode 通过 SQLite 数据库构建了一套完整的持久化方案:
- 跨会话记忆:使用本地 SQLite 数据库存储多轮对话历史和任务状态。当开发者关闭终端后重新打开,Agent 不会一脸懵地问"我们之前在做什么来着?"
- 断点续传:开发者可以在重启工具甚至重启机器后,随时恢复之前的会话。这使得处理长达数天的复杂开发任务成为可能——你可以下班回家,第二天接着上次的进度继续
- 全局指导文件:通过
AGENTS.md等蓝图文件建立稳定的项目规则,不受对话轮次影响。这些文件在每次对话开始时都会被读取,确保 Agent 始终遵循项目的编码规范和架构约定。这其实也是 OpenClaw 的主要记忆存储方式(如SOUL.md定义 Agent 性格,USER.md存储用户的个人偏好和工作习惯) - 自动压缩机制(Auto Compact):系统会实时监控 Token 使用情况。当达到 95% 的限制阈值时,自动触发摘要流程——将已完成的工作、当前活动的文件路径和剩余待办事项总结成精炼的上下文,并开启新会话。这样一来,Agent 既不会因为上下文溢出而崩溃,又能保留最关键的任务状态
值得展开说说 Auto Compact 机制,因为它是整个持久化方案中最精妙的设计。
想象一下:你和 Agent 已经进行了 50 轮对话,讨论了架构设计、实现了 3 个核心模块、修复了若干 bug。此时上下文窗口即将耗尽。如果直接截断历史对话,Agent 就会失去所有前因后果。而 Auto Compact 会在触发阈值时执行以下操作:
- 将当前完整的对话历史交给一个专门的"摘要模型",生成结构化的任务摘要
- 摘要中包含:已完成的任务列表、当前正在进行的工作、待办事项、关键的架构决策、活跃文件路径
- 用这个摘要作为新会话的初始上下文,开始一段全新的对话
从开发者的体验来看,这个过程几乎是无缝的——Agent 在压缩前后的行为保持连贯,只是底层的对话窗口悄悄地"换了一帧"。这有点像人类大脑的记忆整理机制:你不需要记住今天上午写的每一行代码的细节,但你记得"上午完成了用户注册模块,下午要开始做登录"。
第三层:结构化上下文管理(编排者-子代理模式)
前两层分别解决了"实时感知"和"持久化存储"的问题,但还有一个更隐蔽的挑战:上下文膨胀。
即使有了 SQLite 存储和自动压缩,如果一个复杂任务需要 Agent 搜索 100 个文件、读取 50 个函数定义、分析 20 个依赖关系,这些中间过程本身就会把上下文窗口塞满。为了解决这个问题,OpenCode 采用了 编排者-子代理(Orchestrator-Subagent) 架构。其设计核心在于代理与子代理的多层级编排体系:
- 主代理:开发者直接交互的主要对象,负责管理整个对话流和决策过程。主要功能是控制权限、拆解任务,分为 Build 和 Plan 两种模式,一般使用最高级模型
- 子代理(Subagents):由主代理通过内置的
task工具自动调用,或由用户在对话框中通过@符号手动唤起(如@explore)。每个子代理在独立的上下文窗口中运行
这种分离的好处是什么?
上下文净化。复杂的研究或搜索任务由子代理在独立会话中执行。子代理产生的海量搜索结果和冗长日志不会污染主会话的上下文,只有最终的精炼结论会被返回给主代理。
这种模式的效果有多显著?数据说话:它曾成功将相当于 200 万个 Token 的工作量精简并适配到 15.7 万 Token 的主对话流中。也就是说,超过 90% 的"噪音"被子代理在独立空间中消化掉了,主代理只需要处理最终的"干货"。
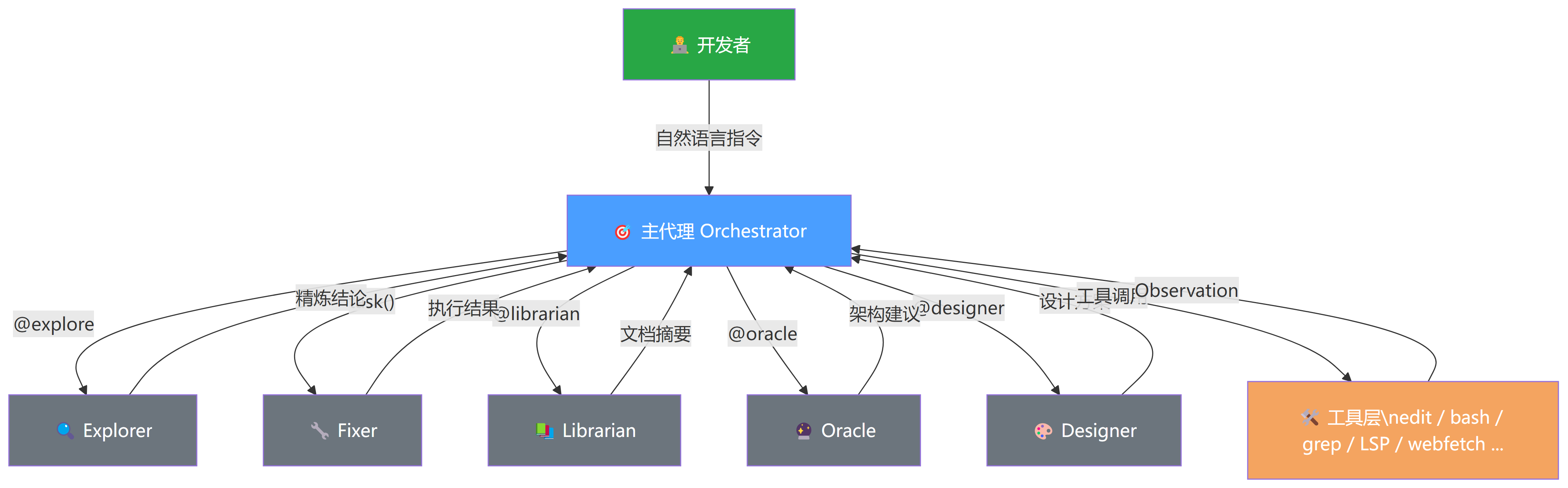
工具层内置了丰富的能力集:edit、write、patch、read、grep、glob、list、bash、webfetch、task、todo、skill、LSP 等等。当主代理遇到复杂问题时,它会使用 task 工具派生(Spawn)一个子会话。子代理在独立的上下文窗口中运行,产生的冗长搜索记录、日志或中间过程不会污染主会话的上下文窗口。子代理完成任务后,仅将精炼后的结论返回给主代理,主代理再将其整合进全局计划中。
除此之外,系统还配备了一系列保障机制来确保整个流程的可靠性:
- 权限网关:敏感操作(如删除文件或推送代码)可配置为"询问(Ask)"模式,强制要求人类介入。这是 Agent 自动化和人类控制之间的重要平衡点
- 死循环检测(Doom Loop Detection):如果系统检测到同一个工具调用连续三次失败且输入完全一致,会自动将该工具权限提升为"询问",强制人类干预以打破循环。这个机制看似简单,但在实际使用中拯救了无数次"Agent 陷入无限重试"的窘境
- 快照恢复:每一轮工具执行前,系统会利用 Git 机制捕获当前工作区状态(Snapshot),若执行出错可随时回滚。这给了开发者一个"后悔药"——不管 Agent 做了什么,你都可以一键恢复到之前的状态
多模型分配:让专业的人做专业的事
解决了上下文管理问题后,另一个工程挑战浮出水面:成本与效率的平衡。
不是所有任务都需要最强的模型。用 Claude Opus 去做一个简单的 grep 搜索,就像请大学教授帮你算小学数学题——能做到,但完全没必要。而在实际开发中,一个完整的功能实现可能包含数十次工具调用,其中大部分都是搜索文件、读取内容这样的简单操作。如果每次调用都使用最强模型,成本会迅速膨胀到不可接受的程度。
来看一组数据:根据 SWE-bench 排行榜的统计,在标准化的编码任务中,不同模型的平均 API 调用次数从 33 次(Claude 4.5 Opus)到 60 次(MiniMax M2.5)不等,单个任务最多可达 100 次以上。从 Agent 的工作流来看,大部分步骤都是文件浏览、目录探索和代码搜索(探索阶段),真正的代码编辑和写入只占一小部分。如果全程使用最高级模型(如 Claude Opus),根据 Aider 编码基准的数据,在涉及多轮迭代的复杂真实项目任务中,单次任务成本可能达到数美元量级。而 RouteLLM 的研究表明,通过智能的模型路由——让简单任务使用快速模型,复杂任务才动用高级模型——可以在保持 95% 性能的前提下实现 45%-85% 的成本降低,同时响应速度还更快。
异步调用优化
在讨论多模型分配之前,先聊一个前置问题:同步交互的瓶颈。
传统的 Coding Agent 交互模式是同步的——你发一条指令,然后盯着屏幕等 Agent 完成。对于耗时几分钟的简单任务来说这没什么问题,但当一个大型重构需要运行半小时甚至更久时,这种"人等机器"的模式就变得非常低效。
这个问题在实际工作中表现得尤为突出。你可能正在 Agent 上跑一个"给整个项目添加单元测试"的任务,这需要 Agent 逐个文件分析、编写测试、运行验证。整个过程可能持续 30 分钟到一个小时,而这段时间你只能盯着终端看进度条——或者切到别的窗口做事,但又担心 Agent 在某个步骤卡住了需要你介入。
典型的解决方案是 OpenClaw 支持的 Pi Agent。它主要解决的是通用工具调度能力的交互规则:用户通过任意客户端发送指令后即可离开,代理完成后会主动发消息告知进度,中间不再有同步监控思考过程的需要。这让开发者可以"发射后不管"——发完指令去开个会、喝杯咖啡,回来时任务已经完成了。
这种异步模式的价值不仅仅是节省等待时间。更重要的是,它释放了开发者的注意力。人类的注意力是有限资源——如果你把注意力锁在一个正在自动运行的 Agent 上,你就无法同时进行其他需要深度思考的工作。而异步模式让你可以同时管理多个 Agent 任务,实现真正的"一个人当一个团队用"。
事实上,异步执行已经成为 2025-2026 年 Coding Agent 的标配能力。除了 OpenClaw 的 Bot 方案,主流产品也纷纷跟进:
- Claude Code on the Web:用户在 Web 界面提交任务后,代码在 Anthropic 管理的隔离 VM 中异步执行。提交后可直接关闭浏览器,甚至通过 iOS App 监控进度。更有趣的是它的 会话穿梭 能力——通过
/teleport命令可以将 Web 云端的会话无缝拉回本地终端继续工作,反过来也可以用&前缀将本地任务发送到云端后台执行 - OpenAI Codex:集成在 ChatGPT 中的编码代理,每个任务在隔离的云沙箱(microVM)中运行,默认无网络访问以确保安全。支持并行多任务,完成后自动创建 PR
- GitHub Copilot Coding Agent:直接在 GitHub Issue 中
@copilot或将 Issue 分配给 Copilot,Agent 在云沙箱中异步完成从代码分析到 PR 创建的全流程,并自动分配人类 reviewer 进行审查循环
这些产品的共同趋势是:异步不再是可选项,而是默认的工作模式。开发者的角色正在从"盯着终端等结果"转变为"批量派发任务、定期检查进度、在关键节点做决策"。
任务执行者细化
专业的人做专业的事。将不同的子任务分配给不同的 Agent,从而获得专用 prompt 优化以及专用 model 优化,在速度和成本之间取得最佳平衡。
例如,oh-my-opencode-slim 将角色分配为六个被称为 "万神殿"(Pantheon) 的专业代理,各自承担特定的职责:
| 角色 | 职责 | 模型选择倾向 |
|---|---|---|
| Orchestrator(协调者) | 核心指挥官,负责确定最优路径、平衡进度与成本,并向其他专家代理分发任务 | 高级模型 |
| Explorer(探索者) | 负责代码库侦查,深入理解项目模式、文件结构及隐藏的逻辑 | 快速模型 |
| Oracle(神谕) | 战略顾问,在重大架构决策时提供指引,并作为最后的调试手段 | 最高级模型 |
| Librarian(图书管理员) | 负责检索外部知识,将零散的信息整合为深刻的理解 | 中等模型 |
| Designer(设计者) | UI/UX 实现专家,确保界面交互的美学和功能性 | 中等模型 |
| Fixer(修复者) | 快速执行专家,负责将设计规格和想法转化为最终的代码实现 | 快速模型 |

该项目默认配置 Orchestrator 作为主入口,并集成了 Exa 网络搜索等组件以支持这些角色的工作。
这样一来,一个简单的 grep 搜索交给 Explorer 用 Haiku 模型执行(响应速度快、成本低),代码库的结构分析交给 Librarian 用中等模型处理,而复杂的架构决策才需要 Oracle 用 Opus 级别的模型来深度思考。整体成本可以降低数倍,响应速度也大幅提升,同时不牺牲关键决策的质量。
这种分配策略的关键在于 "何时升级" 的判断。一个好的 Orchestrator 需要准确判断当前任务的复杂度:如果一个看似简单的 bug 修复实际上涉及到分布式事务的一致性问题,那就需要及时升级到 Oracle 来分析。反过来,如果一个听起来很复杂的需求实际上只需要按照固定模板生成代码,那交给 Fixer 就足够了。
这个判断过程本身就是一种元认知(Meta-Cognition)——Agent 需要"认识到自己不知道什么"。这比仅仅"完成任务"要难得多,也是当前多 Agent 架构中最值得关注的研究方向之一。
从某种角度来说,这种多模型分配策略其实也是对人类团队协作模式的一种映射——一个成熟的工程团队里,不会让架构师去写每一行代码,也不会让实习生去做系统设计。AI Agent 团队的分工逻辑也是如此。
打破物理边界:远程访问与自动化控制
Coding Agent 在本地终端跑得很好,但有一个非常现实的问题:开发者不可能一直坐在电脑前。
现代 AI Agent 在处理大型任务时需要利用本地计算能力和本地数据,而加上外部访问能力,可以允许用户在任何地方都能随时调用到这些能力。开发者不再需要守在电脑旁监控长达数小时的自动化任务,通过远程接入即可随时查看进度或进行微调和进一步决策。
但这里有一个体验上的关键矛盾:TUI(Terminal User Interface)的命令行在本机上用起来得心应手,但在其他设备上——尤其是手机和平板这样的触控设备上——几乎是无法使用的。你很难在一块 6 英寸的触摸屏上高效地操作一个全屏终端界面。
那么,如何在远程设备上也能流畅地使用 Coding Agent?目前业界主要有两种方案。
OpenClaw 的 Bot 方案
作为最近很火的 AI Agent,OpenClaw 选择了一条"借道"的路线:利用现有社交软件的 Bot 能力来实现远程控制。
在技术实现上,OpenClaw 用 systemd 将 gateway service 注册为一个 daemon 守护进程,内部维护了一个 WebSocket 实例(默认端口 18789)作为通信总线。利用各个社交软件对 Bot 的支持能力(如 Discord、Telegram 等),经过一系列极其复杂的配置,让 Bot 能够与本地服务进行通信。
它的 Pi Agent 工作流如下:
消息输入(用户/Trigger)→ Context 检索(长期记忆: USER.md, SOUL.md)→ Prompt 组装 → RPC 调用 → Pi Agent → 工具链(tools/skills/MCP)→ 流式返回 Response
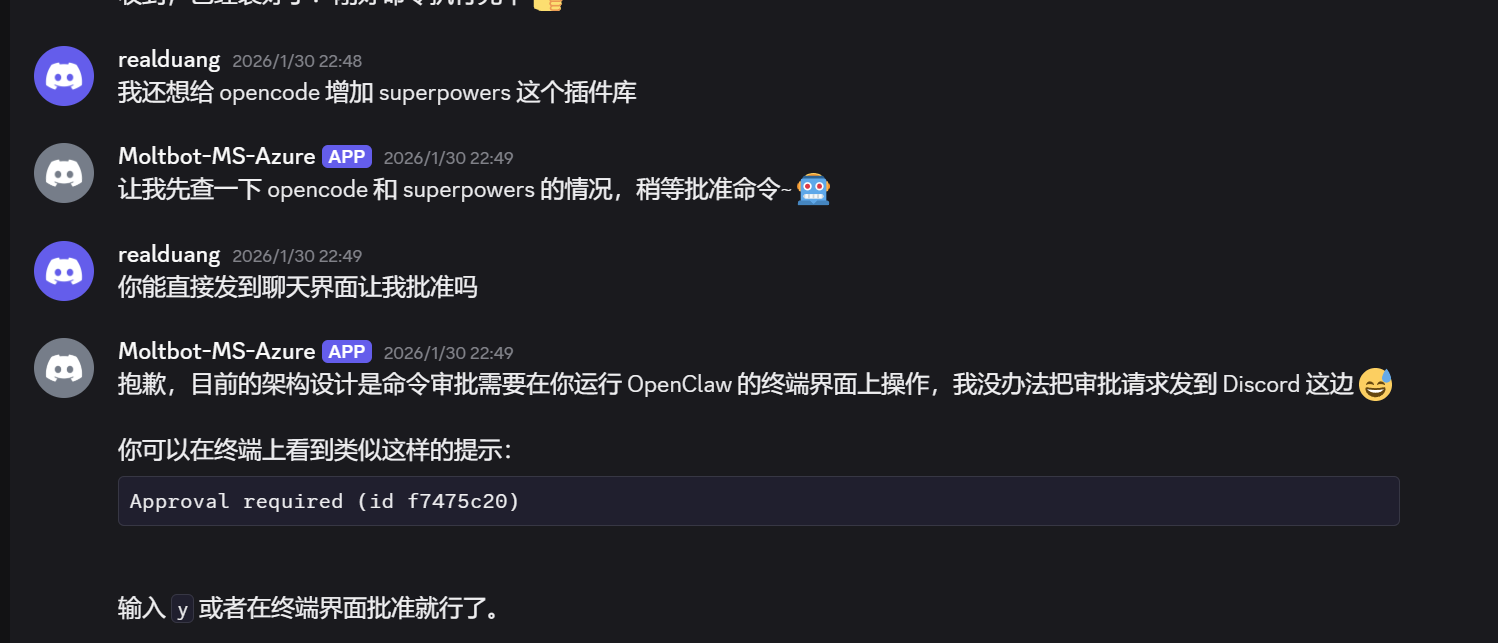
但问题也很明显——社交软件的 Bot 并不是天生为 Coding Agent 场景设计的,接入方式有极大的适配和维护成本,而且会有各种各样的限制:
- 无法实时查看任务进度:大部分 Bot 协议不支持流式更新,你发完指令后只能干等最终结果
- 仅支持一问一答:任务运行中如果需要用户补充决策(比如"这里有两种实现方案,你选哪个?"),Bot 没有好的方式把这个请求传递给你
- 消息格式受限:代码差异、文件树、错误日志这些结构化信息在社交软件的对话气泡里很难优雅地展示
- 审批操作困难:命令审批需要在终端界面上操作,无法通过 Bot 远程完成
OpenCode Remote 的 Web 方案
正因为 Bot 方案的种种限制,OpenCode Remote 选择了另一条路——专门面向 Coding Agent 优化的 Web 方案。为了尽可能自由地扩展和展示各种工具调用的详细信息,Web 天然是最合适的载体,同时也能更好地进行多设备端的适配。
内网穿透:Cloudflare Quick Tunnel
远程访问面临的第一个技术挑战是:开发者的工作站通常在内网中,没有公网 IP,外网无法直接访问。
OpenCode Remote 借助 Cloudflare Quick Tunnel 解决了这个问题。它的原理是利用隧道机制,通过在本地运行 cloudflared 守护进程主动向外发起连接(而非等待外部连入),在 Cloudflare 的边缘网络上建立一个临时的公网入口。这样开发者无需公网 IP 或配置复杂的防火墙,就能从外网安全地访问本机。
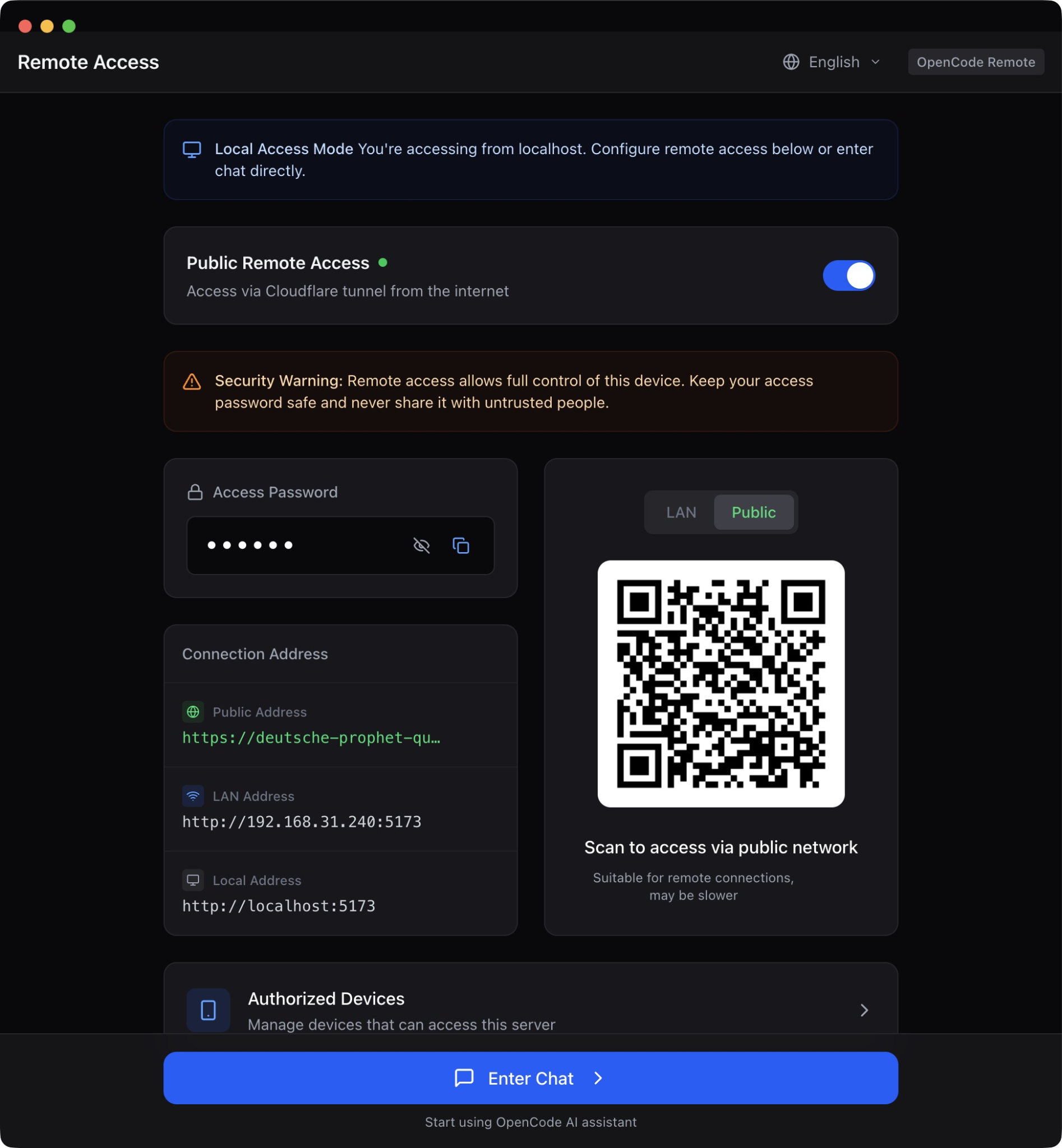
关键的是,因为 Cloudflare 在这方面堪称"大善人",通过该隧道技术的内网穿透完全匿名且免费,非常适合做零配置的临时穿透方案给开源项目使用。
Tunnel 的工作流如下:

四层安全校验
与 Bot 方案依赖社交软件的防御策略不同,内网穿透的方案需要自己管理连接安全性,而不是依赖各个社交软件的防御策略。OpenCode Remote 使用了四层安全校验保证连接的可靠:
- Cloudflare Tunnel + Zero Trust 验证:保证 HTTPS 连接本身的安全性。核心设计原则是 Outbound Only——不需要开放任何入站端口或配置防火墙规则,攻击者无法直接扫描或攻击你的源服务器
- 服务端绑定回环端口:确保 OpenCode Server 设置为 loopback(
127.0.0.1),防止端口直接暴露在公网,仅允许通过隧道转发的请求通过 - 一次性 PIN 码校验:每次启动远程访问时生成一个临时 PIN,首次连接必须提供正确的 PIN 才能建立会话,防止未授权访问和 DDoS 攻击
- 设备管理授权认证:新设备首次发起访问请求时,主机会收到请求端的 IP、OS、浏览器等信息。主机授权通过后生成 fingerprint 记录在本地。之后所有的 HTTP 请求会校验 fingerprint,不符合的请求会被直接 reject
在这条安全隧道之上,系统利用 SSE(Server-Sent Events)技术,将 AI 在本地执行代码、查看日志的动态实时"广播"到你的移动端设备上。相比 WebSocket 的双向通信,SSE 在这个场景下更加合适——Agent 的执行过程本质上是一个单向的信息流,只需要服务端向客户端推送即可,不需要客户端频繁发送数据回去。从而实现了实时同步的流式传输与交互效果。
为什么选择 SSE 而不是 WebSocket?这个技术选型值得展开说说。WebSocket 是全双工通信协议,适合聊天室、在线游戏等需要频繁双向通信的场景。但 Coding Agent 的远程监控场景有一个明显特征:信息流是极度不对称的。服务端(Agent)需要持续推送大量信息(代码变更、终端输出、诊断结果),而客户端(开发者的手机)只需要偶尔发送简短的指令("继续"、"取消"、"换个方案")。在这种不对称场景下,SSE 有几个显著优势:
- 更简单的实现:SSE 基于标准 HTTP,不需要专门的协议升级和握手过程
- 天然支持断线重连:SSE 内置了
Last-Event-ID机制,网络波动后可以自动恢复,而 WebSocket 断线后需要手动重建连接 - 更友好的防火墙穿透:由于 SSE 就是普通的 HTTP 请求,它在企业网络环境中更不容易被防火墙拦截
- 更低的服务端资源消耗:不需要维护长连接的状态,减少了服务端的内存开销
用户发送的偶尔指令则通过普通的 HTTP POST 请求完成,整个架构干净利落。
灵魂之问:控制权到底在谁手里?
聊了这么多 OpenCode 的实现,而与大家所熟知的 Claude Code 和 Codex 一样,它们都能做到代码的自动化闭环改进。但事实上,它们的实现原理是不完全一样的。
核心区别的本质在于:控制权在谁手里。
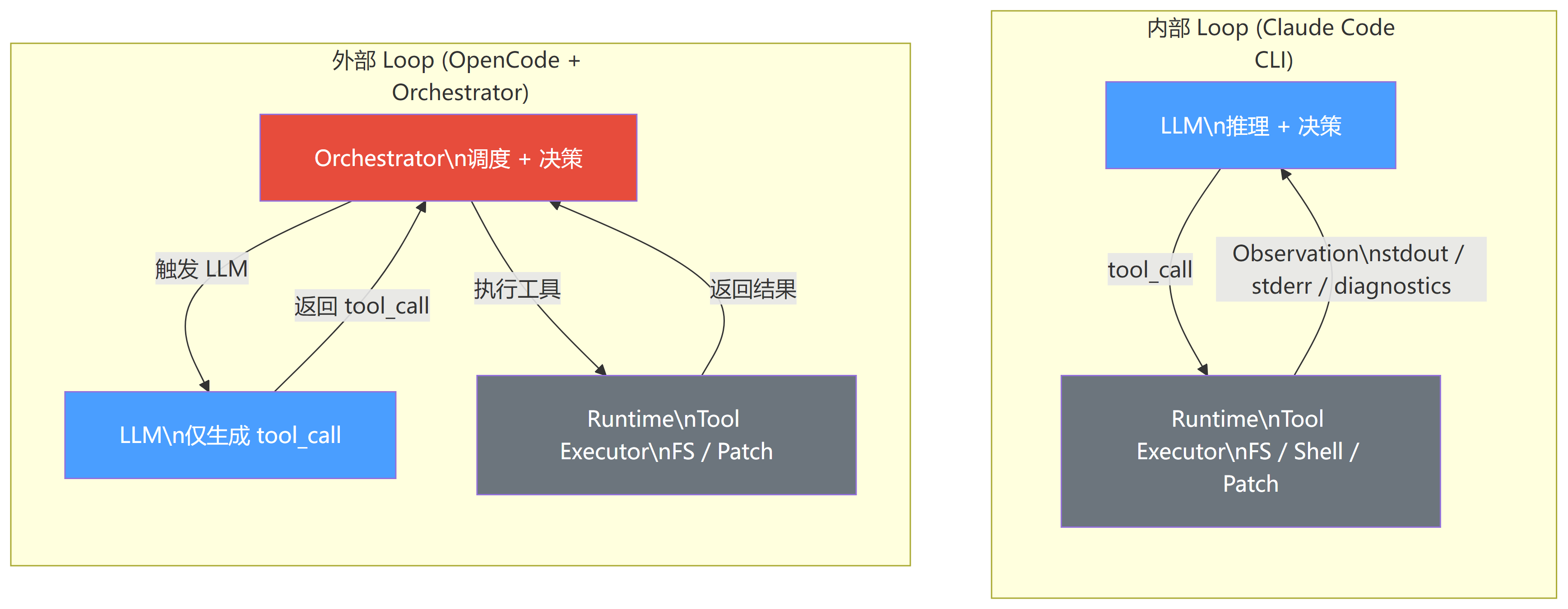
内部 Loop:Claude Code CLI
这是狭义上的 Agent Loop:
LLM 输出 → Runtime 执行 → Observation → 立即下一步 → Loop
整个任务执行过程完全在 LLM 内部闭环。甚至 bash 的 stdout/stderr 都可以直接获取到,因此推理模型可以连续思考、修正 bug,直接操纵文件系统、Shell、Patch,连续执行直到任务完成,状态树完整且连续。
虽然 Claude Code 引入了 "h2A" 异步双缓冲消息队列,支持用户在任务中途实时注入指令或纠偏,但默认是闭环自动执行的。像 Claude Code 与 Codex 这种拥有专为自家工具调优的推理模型,大多走的就是这条路径。因为没有通用性,大多没有也没必要开源。
外部 Loop:OpenCode + Orchestrator
这是另一种完全不同的设计哲学:
LLM 输出 → 返回外部 Orchestrator → Orchestrator 决定下一步 → Runtime 执行 → 返回
Agent 内核本身没有 Loop,每步都是"外部触发"。LLM 不知道全局状态,只看到上一次的输出,自动化完全依赖外部 Orchestrator 调度。简单来说,LLM 仅仅只是作为 OpenCode 所调用的一个被动工具,并不需要模型本身拥有 reasoning 能力。
两种路径的权衡
这两种架构各有其适用场景,选择哪种取决于你的核心诉求。
内部 Loop(以 Claude Code 为代表) 的优势在于状态连续、闭环流畅。因为 LLM 自己掌控整个执行循环,它对任务的全局理解更完整,可以做出更连贯的决策。想象一下一个经验丰富的工程师独自完成一个任务——他脑子里有完整的上下文,不需要别人反复提醒"你之前做了什么"。但代价是高度耦合,难以替换模型。你的 Agent 和你的模型绑定在一起,一荣俱荣。
外部 Loop(以 OpenCode 为代表) 的好处是不依赖 LLM 基模优化,任何模型都能得到不错的效果。工具链和插件生态因为独立扩展,不需要注册到 Runtime 内核,因此构建更灵活。你可以今天用 Claude,明天换 GPT,后天试试 DeepSeek,而整个工具链和工作流不需要任何改动。但由于模型获取 context 不连续——它每次被调用时只看到上一次的输出,不知道更早之前发生了什么——闭环状态不如内部 Loop 连续流畅。
用一个更直观的类比来总结:
| 维度 | 内部 Loop | 外部 Loop |
|---|---|---|
| 类比 | 全职工程师 | 外包顾问 |
| 上下文 | 完整连续,了解全部历史 | 碎片化,每次只了解当前任务 |
| 灵活性 | 低,深度绑定特定模型 | 高,随时切换模型 |
| 一致性 | 强,决策连贯 | 弱,可能出现前后矛盾 |
| 成本优化 | 难,全程需要高级模型 | 易,可按任务分配模型 |
| 开源生态 | 通常闭源 | 通常开源 |
从产业格局来看,像 Claude Code 和 Codex 这样的产品走内部 Loop 路线,深度绑定自家模型以追求极致体验。而 OpenCode 和 VSCode 中的 Copilot 走外部 Loop 模式,好处是能够更多接入和兼容不同模型,为用户提供更多选择。
值得注意的是,这两种路径并不是完全互斥的。我们已经开始看到一些混合方案的出现:例如在外部 Loop 的框架中,对于关键的决策步骤使用"长上下文"模式(类似内部 Loop),而对于简单的工具调用则回退到外部调度。这种"选择性闭环"可能会成为未来的主流趋势。
这两种路径的分野,本质上是 AI 产业"垂直整合 vs 开放生态"这一经典命题的又一次具象化——就像当年 iOS 和 Android 的选择一样,没有绝对的对错,只有适合与否。
结语
从 Tab 补全到自主编程,Coding Agent 的进化速度远超预期。回顾全文我们可以看到,这条进化之路上的每一步优化都在解决一个核心矛盾:如何让 AI 像人类工程师一样,持续、可靠、高效地完成复杂的工程任务。
上下文管理让 Agent 拥有了"记忆",多模型调度让它学会了"分工",远程协作让它突破了"物理限制",安全控制则确保了整个过程的"可控性"。这些看似"基础设施"层面的优化,实际上决定了 Coding Agent 能否从"玩具"进化为真正的"生产力工具"。
但我们也必须诚实地面对现实:即使有了这些精巧的工程设计,当前的 Coding Agent 依然无法完全替代人类开发者。它擅长的是"执行"——把一个清晰的需求转化为代码。而人类开发者最不可替代的价值在于"判断"——决定什么该做、什么不该做、以及在多种可行方案中选择最合适的那个。
对于开发者来说,最重要的或许不是选择哪一种工具,而是适应一个新的事实:我们正在从"写代码的人"变成"指挥代码的人"。而如何成为一个好的指挥者——清晰地表达意图、精准地审查结果、在正确的时机做出正确的决策——这可能是接下来每个开发者都需要修炼的新技能。
毕竟,指挥家不需要会演奏每一种乐器,但他必须知道每一种乐器该在什么时候响起。
参考资料
- OpenCode — 开源 AI 编程代理,基于终端 TUI,支持多模型切换、LSP 集成与编排者-子代理架构
- OpenClaw — AI Agent 框架,支持 Pi Agent 异步执行、Discord/Telegram Bot 远程控制与长期记忆管理
- oh-my-opencode-slim — OpenCode 的"万神殿"多角色配置方案,将任务分配给六个专业代理以优化成本与速度
- OpenCode Remote — OpenCode 的远程访问方案,基于 Cloudflare Tunnel 内网穿透与 SSE 实时推送
- Halo — 开源桌面应用,为 Claude Code 提供图形化界面,支持 Space 隔离工作区、Artifact 实时预览、远程访问与 AI Browser 等能力
- Claude Code — Anthropic 官方的 AI 编程代理,采用内部 Loop 架构实现闭环自主编程
- Language Server Protocol (LSP) — 微软定义的语言服务协议,为 Coding Agent 提供实时代码诊断与导航能力
- Cloudflare Quick Tunnels — 零配置、免费的内网穿透方案
- SWE-bench — 标准化的 Coding Agent 基准测试平台,提供工具调用次数与每任务成本数据
- Aider LLM Leaderboards — 多模型编码能力与成本对比排行榜
- RouteLLM (LMSYS) — 智能模型路由框架,实现 45%-85% 的成本降低